Ta technologia to wentyl bezpieczeństwa dla rozwoju SI. AMD tego przypilnuje
Zapoczątkowana przez OpenAI i Microsoft rewolucja w formie tak zwanej generatywnej sztucznej inteligencji niesie za sobą wiele problemów i zagrożeń. Wiodące na dziś technologie mają charakter w dużej mierze zamknięty i własnościowy. AMD, jedna z ważniejszych firm dla rozwoju GenAI, ma czytelny komunikat dla inwestorów i klientów. Open-source to przyszłość. Co zabawne, przytakuje temu nawet Microsoft.

OpenAI dawno, dawno temu miało być spółką o charakterze w dużej mierze filantropijnym - i opracowywać wolne rozwiązania związane ze sztuczną inteligencją, które w jakiś sposób wpływałyby korzystnie na rozwój ludzkości. O tej misji nieco zapomniano - zależna dziś od Microsoftu spółka niewiele różni się od innych firm informatycznych, dbając o zysk. I pilnując swoich wywrotowych technologii, z GPT na czele, przed kopiowaniem i plagiatowaniem.
Nietrudno patrzeć na taką zmianę nastawienia nieprzychylnym krokiem, ale niewykluczone, że gdyby nie komercjalizacja działań OpenAI i pomoc ze strony Microsoftu, rzeczona rewolucja nigdy by nie nastąpiła. Tymczasem trwa bezprecedensowy boom na usługi oparte o generatywną sztuczną inteligencję, a eksperci często porównują GenAI do innych informatycznych rewolucji na miarę publicznej chmury czy smartfonu.
Każdy chce być nowym IBM-em. Choć nie każdy chce skończyć jak IBM.
Tego rodzaju przełomy w IT niemal zawsze finansowane były przez duże i nastawione na zysk korporacje. Ale też niemal zawsze z czasem doczekiwały się przeciwwagi w formie wolnego i otwartego oprogramowania czy otwartych architektur sprzętowych. Mając na uwadze strukturę rynku i podaż ze strony innych podmiotów niż tylko majętne korporacje jest to nieuniknione.
Generatywna sztuczna inteligencja gruntownie namieszała w branży. Jednym z moich ulubionych przykładów jest Nvidia, która za sprawą GenAI stała się jedną z najpotężniejszych firm na świecie i największym - jeśli za miarę wziąć rynkową kapitalizację - podmiotem związanym z elektroniką w historii. Co w tym zabawnego?
Przydarzyło się to Nvidii ciut niechcący. Okazało się, że jej karty graficzne do renderowania gierek 3D akurat świetnie się sprawdzają do przeliczeń związanych z uczeniem maszynowym (ML) i sztuczną inteligencją. A prace Nvidii nad SI do akceleracji przeliczeń związanych z renderowaniem grafiki zapewniły firmie szczególną startową pozycję, czyniąc z niej idealnego partnera dla operatorów centrów danych.
AMD tę rewolucję nieco przespało. Nie prowadziło tak zaawansowanych badań nad sztuczną inteligencją co Nvidia, wierząc przede wszystkim w surową moc rasteryzacji, w czym karty AMD Radeon są akurat bardzo dobre. Zaległości zostały w dużej mierze nadrobione - układy Epyc i akceleratory Instinct są uważane za znakomite produkty i znaleźć je już można w większości najważniejszych centrów danych na świecie. Opóźnienie AMD nieuchronnie jednak zapewnia Nvidii ogromną przewagę. Rozsądną strategią wydaje się więc obranie drogi tego podmiotu, który zamiast na własnościowe rozwiązania stawia na te otwarte. A tak się akurat składa, że AMD taką politykę prowadzi od dawna. I wie jak ją skutecznie realizować.
AMD ROCm. Czyli programowanie centrum danych technologiami open-source.

ROCm to oprogramowanie firmy AMD do programowania jednostek graficznych (GPU). ROCm obejmuje wiele dziedzin: ogólne obliczenia na jednostkach graficznych (GPGPU), obliczenia o wysokiej wydajności (HPC), obliczenia heterogeniczne. ROCm składa się z zestawu sterowników, narzędzi deweloperskich i interfejsów programistycznych (API), które umożliwiają programowanie GPU od niskopoziomowych jąder do aplikacji użytkownika końcowego.
ROCm oferuje szereg optymalizacji dla zadań związanych z sztuczną inteligencją (AI) i HPC, takich jak duże modele językowe, wykrywanie i rozpoznawanie obrazów/wideo, nauki przyrodnicze i odkrywanie leków, jazda autonomiczna, robotyka i wiele innych. ROCm obsługuje również szerszy ekosystem oprogramowania AI, w tym otwarte frameworki, modele i narzędzia.
Najnowsze teksty o sztucznej inteligencji na Spider’s Web:
AMD ROCm obsługuje wiele języków programowania dla zadań HPC, dając programistom wybór narzędzi, które pomogą rozwiązać problem, nad którym pracują - w tym OpenMP, HIP, OpenCL i Python. ROCm zawiera również szeroką gamę bibliotek matematycznych i komunikacyjnych, które pomagają programistom dostarczać bardziej funkcjonalny i wydajny kod HPC. ROCm zawiera również kompleksowy zestaw narzędzi, które zapewniają programistom i badaczom elastyczne zarządzanie, kontrolę jakości i monitorowanie. Oprogramowanie AMD obsługuje wiodące narzędzia konteneryzacji, takie jak Docker, Singularity, Kubernetes i Slurm, które ułatwiają wdrażanie i zarządzanie dużymi klastrami GPU AMD dla AI i HPC.
ROCm jest otwartym i uniwersalnym oprogramowaniem, jest również kompatybilny z różnymi układami GPU od AMD, Nvidii i Intela. Ma niskie wymagania i koszty wdrożenia i zarządzania. Programiści i badacze mogą wybrać najlepsze narzędzie i język dla swojego problemu, nie będąc ograniczonymi do jednego dostawcy lub standardu. Mogą korzystać z otwartych i uniwersalnych interfejsów, które umożliwiają łatwe tworzenie, udostępnianie i ponowne wykorzystywanie kodu i modeli. Mogą również korzystać z otwartych i aktualnych źródeł danych i wiedzy, które pomagają w rozwiązywaniu nowych i złożonych problemów.
Firma zaprezentowała właśnie AMD ROCm 6, które na najnowszych akceleratorach SI od AMD - do których wrócimy za chwilę - przetwarza open-source’owy opracowany przez Metę Duży Model Językowy Llama 2 nawet ośmiokrotnie szybciej niż przy użyciu oprogramowania poprzedniej generacji.

To jednak nie koniec nowości. Dodano obsługę FlashAttention (metoda optymalizacji uwagi dla LLM, która polega na wykorzystaniu pamięci podręcznej GPU do przechowywania kluczy i wartości uwagi, pozwalając na zmniejszenie zużycia pamięci i zwiększenie przepustowości obliczeń dla LLM), HIPGraph (biblioteka do programowania grafów na GPU, która wykorzystuje język HIP, który jest kompatybilny z CUDA i OpenCL - umożliwia łatwe tworzenie, analizę i wizualizację grafów na GPU, wykorzystując takie algorytmy jak BFS, DFS, PageRank, SSSP i inne) i vLLM (szybka i łatwa w użyciu biblioteka do wnioskowania i serwowania LLM).
A co z tymi akceleratorami? AMD to jednak firma przede wszystkim od sprzętu. MI300X i MI300A są zaprojektowane z myślą o GenAI.

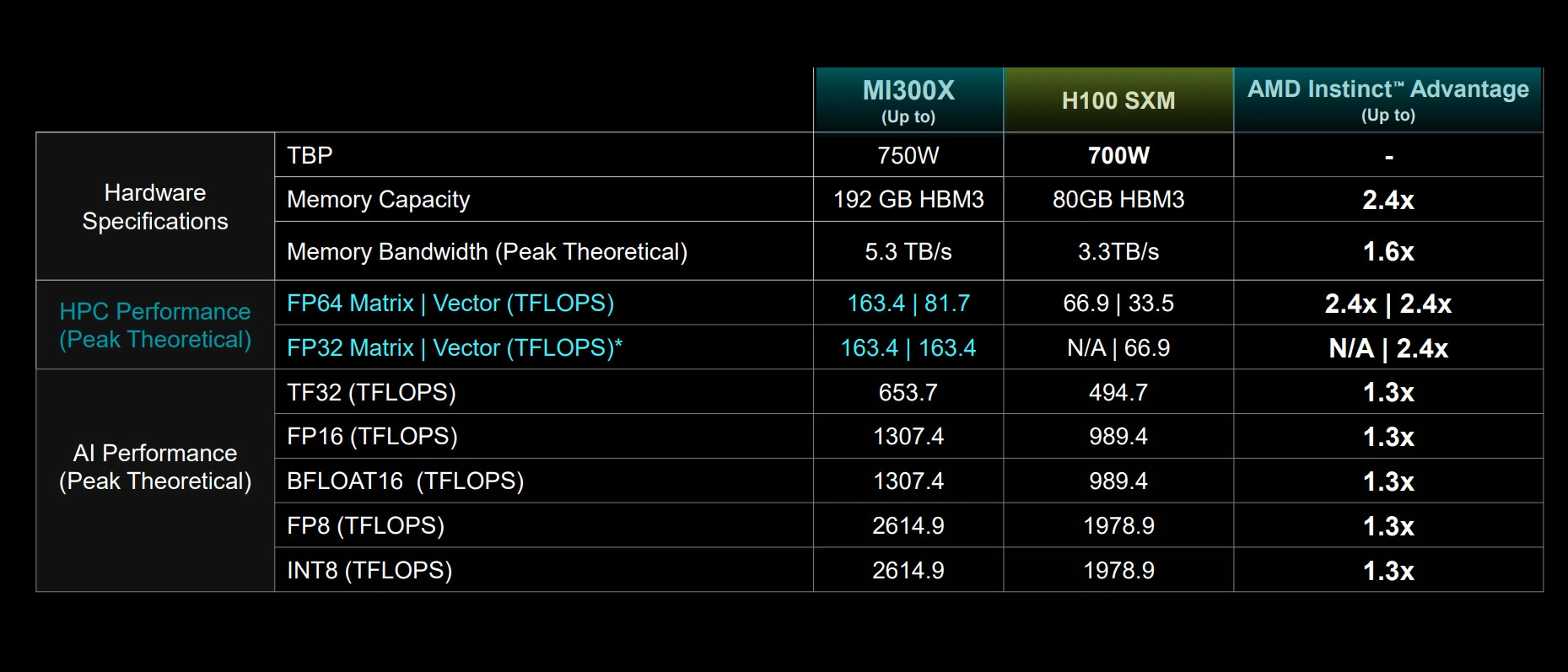
Akceleratory MI300X będą wykorzystywać nową mikroarchitekturę CDNA 3 i zapewniać w porównaniu do MI250X o 40 proc. więcej jednostek obliczeniowych, 1,5-krotnie większą objętość pamięci, 1,7-krotnie wyższą przepływność pamięci i obsługę nowych formatów obliczeniowych, w tym FP8 czy sparsity. Zawierają 192 GB pamięci HBM3, w wspomniana przepływność to 5,3 TB/s.

Składająca się z ośmiu MI300X AMD Instinct Platform jest podobno o 1,6 raza wydajniejsza w przetwarzaniu LLM od Nvidia H100 HGX, czyli bezpośredniego konkurenta. Co prawda zapowiedziano już H200, ale ten ma się pojawić dopiero w połowie przyszłego roku - i podobno ma nie być aż tak wydajniejszy. Tymczasem AMD jest już gotowe do obsługi klientów.

A ich przedstawiciele jak najbardziej byli obecni na premierze. Pojawili się rzecznicy i menedżerowie Della, HP, Lenovo, Mety, Microsoftu i Oracle’a. Skąd te korporacje, skoro przed chwilą budowaliśmy narrację o rozwiązaniach open-source? Choć AMD stawia na promocję otwartych rozwiązań, tak natura zamkniętych i otwartych modeli SI jest w odniesieniu do sprawności układu scalonego relatywnie nieistotna, co oznacza, że Instincty najnowszej generacji powinny też rewelacyjnie się sprawdzać w przypadku przetwarzania własnościowych modeli, takich jak GPT. Z kolei Microsoft nie zajmuje się tylko rozwojem SI, to również firma od infrastruktury - i zarabia ogromne pieniądze na hostowaniu w chmurze Azure open-source’owych aplikacji. A to nie koniec nowości.

Drugim z zaprezentowanych akceleratorów jest pierwsze APU dla centrów danych zajmujących się HPS i SI - MI300A. Składa się z ośmiu wysokowydajnych rdzeni CDNA 3, rdzeni Zen 4 (x86) i 128 GB pamięci HBM3. AMD twierdzi, że jest 1,9-raza sprawniejszy energetycznie przy przeliczeniach FP32 HPC i SI od MI250X. Forma APU oznacza zunifikowaną pamięć operacyjną i podręczną dla CDNA 3 i Zen 4, co znacząco ułatwia programowanie modułu.

Najwydajniejsze układy, najsprawniejsze frameworki i współpraca ze wszystkimi programistami, którzy by sobie tego życzyli. Trudno temu nie kibicować.

Interoperacyjność i open-source sprzyjają współpracy i innowacji w dziedzinie SI, ponieważ umożliwiają łatwiejsze dzielenie się danymi, kodem i wynikami między różnymi podmiotami i platformami. Dzięki temu można szybciej i skuteczniej rozwiązywać problemy, tworzyć nowe rozwiązania i poprawiać jakość istniejących produktów i usług. Zwiększają też zaufanie i przejrzystość w dziedzinie SI, ponieważ umożliwiają weryfikację i ocenę działania i skutków systemów SI przez niezależnych ekspertów, użytkowników i społeczeństwo. Dzięki temu można lepiej chronić prywatność, bezpieczeństwo i prawa człowieka, a także zapobiegać nadużyciom i manipulacjom.
Interoperacyjność i open-source promują różnorodność i inkluzję w dziedzinie SI, ponieważ umożliwiają dostęp i udział w tworzeniu i korzystaniu z systemów SI przez osoby i grupy, które mogłyby być wykluczone lub dyskryminowane przez zamknięte i monopolistyczne rozwiązania. Dzięki temu można lepiej reprezentować i zaspokajać potrzeby i oczekiwania różnych społeczności i kultur.

Nie należy przy tym za bardzo dać się ponieść wizji, jakoby AMD wkraczało na rynek jako jakiś zbawca na białym koniu. Nvidia wspiera również rozwój i udostępnianie otwartych bibliotek i narzędzi do SI, takich jak TensorFlow, PyTorch czy RAPIDS. Nvidia angażuje się również w inicjatywy i projekty mające na celu poprawę etyki, bezpieczeństwa i społecznej odpowiedzialności w dziedzinie SI, takie jak Partnership on AI czy AI for Good. Szczególny nacisk AMD na otwartość w połączeniu ze sprawnymi energetycznie i wydajnymi rozwiązaniami sprzętowymi rodzi jednak ostrożny entuzjazm. Rewolucja GenAI na dziś niemal w całości jest sterowana przez małe grono firm z tak zwanego Big Techu. Im większa presja na tworzenie alternatywnych, otwartych rozwiązań, tym lepiej dla całego rynku. A przede wszystkim dla nas - użytkowników tych wszystkich teraźniejszych i przyszłych dobrodziejstw.