Sztuczna Inteligencja w chmurze jest gotowa do wykorzystania w twojej następnej aplikacji
Sztuczna inteligencja to coś, co wciąż wydaje się mocno egzotyczne. Mimo to coraz więcej z nas zdaje sobie sprawę, że korzystamy z rozwiązań opartych na AI (Artificial Intelligence) na co dzień.

Wyciągnij z kieszeni telefon. Włącz aplikację kamery i skieruj obiektyw go na kogoś. Aplikacja natychmiast rozpozna, że w polu widzenia kamery znajduje się osoba. Może nawet pokaże w podglądzie zdjęcia prostokąt otaczający twarz tej osoby. Mimo że prawdopodobnie z tą osobą spotkała się po raz pierwszy.
Dzieje się tak dzięki dokonaniom wielu inżynierów i naukowców z ostatnich kilkudziesięciu lat. Subiektywnie wymienię dwa z nich. W 2001 roku Paul Viola i Michael Jones utworzyli pierwszy model do rozpoznawania obiektów na zdjęciach (głównie twarzy). W 2016 roku Yann LeCun utworzył dojrzałą wersję nowego rodzaju sieci neuronowych o nazwie CNN (ang. convolutional neural network), dzięki którym m.in. tworzenie modeli rozpoznawania obrazu wymaga znacząco mniej mocy obliczeniowej, co z kolei wyzwoliło prawdziwą ‘erupcję’ kreatywności na świecie na polu rozpoznawania obrazu.
Algorytmy rozpoznawania obrazu są tylko wierzchołkiem góry lodowej, mamy obecnie do czynienia z prawdziwą wiosną w obszarze rozwijania sztucznej inteligencji, wręcz każdy miesiąc przynosi nowe i fascynujące aplikacje oraz odkrycia. Gdzie śledzić tę swoistą rewolucję?
Na pewno jest wiele źródeł wiedzy na ten temat. Ja, znowu subiektywnie, podam dwa. Pierwsze to Fundacja OpenAI założona przez Elona Muska, która raportuje regularnie efekty swojej pracy w obszarze robotyki, rozumienia języka naturalnego (Natural Language Processing), podejmowania decyzji i innych dziedzin sztucznej inteligencji. Ciekawym tematem jest tu np. algorytm o nazwie GPT-2, który w zatrważający sposób potrafi generować (albo wykrywać) tzw. fake-newsy. Na przykładzie tego algorytmu łatwo sobie wytłumaczyć niespotykaną do tej pory proporcję fake-newsów w sieciach społecznościowych i w Internecie. Ten przypadek pokazuje, jak mocno dokonania w sztucznej inteligencji zmieniają nasz świat.

Drugim źródłem wiedzy o AI jest strona IBM Research, informująca o dokonywanej przez tę firmę rewolucji w obszarze sztucznej inteligencji. W swoim czasie znany był pojedynek Kasparowa z komputerem IBM o nazwie Big Blue. Teraz ze stron z aktualnościami technologicznego giganta możemy się dowiedzieć o innym komputerze konkurującym z człowiekiem w… debatach. Project Debater jest w stanie wysłuchać argumentacji adwersarza i znaleźć odpowiednie kontrargumenty w dyskusji na praktycznie dowolny temat. Fascynujące? A może przerażające? Jest to kolejny przykład obrazujący, jak obszar sztucznej inteligencji wpływa na nasze życie.
Fascynujący jest na pewno fakt, że wiele dobrodziejstw świata sztucznej inteligencji jest dostępnych na przykład w chmurze IBM Cloud. Nie musimy być od razu Yannem LeCunem, aby wzbogacić nasze aplikacje i skorzystać z dogodnych algorytmów rozpoznawania obrazu, przetwarzania języka naturalnego, lub prostych predykcji. Tego rodzaju serwisy są łatwo dostępne i proste do wykorzystania.
Modele Machine Learning. Od czego zacząć?
W pisaniu dowolnej aplikacji, włączając w to tworzenie modeli na bazie algorytmów sztucznej inteligencji, widzę zawsze 3 podstawowe etapy.
Pierwszy, najprzyjemniejszy dla mnie, etap to budowanie. Budowanie jest mozolne, ale czasem może być połączone z zabawą, testowaniem nowych frameworków i wchodzeniem w nową tematykę (lub w starą tematykę, ale na nowy sposób).
Drugi etap zaczyna się w momencie, kiedy zbudowaliśmy już nasze dziecko i chcemy połączyć z je z istniejącą aplikacją lub w jakiś inny sposób wystawić na świat.
Trzeci etap, akurat dla mnie najmniej ciekawy, wciąż jednak ważny, to kontrola nad produkcyjnym działaniem aplikacji lub konkretnego modelu.
Bardzo przyjemnym odkryciem dla mnie był fakt, że chmura IBM Cloud posiada konkretny zestaw narzędzi dla każdego z tych etapów i pozwala wydobyć przyjemność z każdego z nich.
Buduj
Dla pierwszego etapu budowania modeli przewidziany jest przede wszystkim Watson Studio do testowania modeli w notatnikach Jupyter, budowania przepływów ETL (ang. extract, transform, load), moderowania danych streamingowych, tworzenia sieci neuronowych i dużo, dużo więcej.
Kolejnym narzędziem zaliczanym do pierwszego etapu ‘budowania i zabawy’ jest framework do budowania chatbotów – Watson Assistant, opisany w tym artykule bardziej szczegółowo.
Kolejnym obszarem, gdzie budujemy rozwiązania, jest grupa aplikacji do tworzenia modeli NLP (Natural Language Processing) m.in.: silnik wyszukiwania o nazwie Watson Discovery, albo też Watson Knowledge Studio – framework służący do głębszego rozumienia treści tekstów i dokumentów, np. opisywanych konceptów, osób, miejsc, relacji między tymi rzeczami, etc.
Pokaż swój model światu
W przypadku podstawowej aplikacji do budowania modeli machine learning, Watson Studio, wystawienie modelu wiąże się z wykonaniem komendy deploy i utworzeniem w ten sposób instancji Twojego modelu. Utworzoną w ten sposób instancję należy następnie połączyć z aplikacją za pomocą metod usługi typu REST.
W przypadku wystawiania na świat gotowego czatbota w Watson Assistant, mamy opcję skorzystania z gotowego front-endu z chmury IBM Cloud (tak jak w tym przykładzie) lub utworzenia własnego interfejsu do komunikacji z użytkownikiem.
Osoby zainteresowane znajdą przykładowe scenariusze w tym tutorialu.
Kontroluj swój model w produkcji
Bardzo ciekawą aplikacją pozwalającą na kontrolę tego, co dzieje się z utworzonym modelem, jest Watson OpenScale.
Aby uzmysłowić Wam, jak ważna jest ta aplikacja, zacytuję wspaniałego statystyka Georga Boxa:
To powiedzenie, powtarzane przez wielu statystyków, odkrywa m.in. fakt, że modele są tylko pewnym sztucznym przybliżeniem otaczającego nas świata. Jeśli dodamy do tego fakt, że raz utworzony model jest stały, a nasz świat nieustannie się zmienia, mamy pełny obraz sytuacji.
Dla przykładu załóżmy, że utworzyliśmy nowy model przyznawania kredytów w banku, a następnie bank zmienił istotnie swój profil klientów. Jak dotychczasowy model zmieni zachowanie? Czy wyniki działania modelu będą miarodajne? Które składowe modelu wpływają najmocniej na wynik końcowy? Czy model jest w ogóle fair (w sensie pomijania pewnych grup społecznych jak np. kobiety po 50. roku życia i faworyzowania innych, np. mężczyzn w wieku 25-30 lat)? Na te wszystkie pytania pomaga odpowiedzieć Watson OpenScale.
Watson Studio
Nazwane od nazwiska pierwszego prezesa IBM, Thomasa J. Watsona środowisko łączy dziś ponad 50 różnych technologii, które mogą posłużyć do tworzenia rozwiązań z zakresu:
- Uczenia maszynowego
- Deep Learning
- Analizy obrazów (computer vision)
- Analizy dużej ilości danych (big data)
- Analizy statystycznej.
Watson Studio pozwala tworzyć osobne projekty do różnych rozwiązań. Mogą one zawierać komponenty takie jak notatniki Jupyter (łączące obliczenia z dokumentacją) oraz zbiory danych (na których możemy operować).
Nasz własny notatnik Jupyter
Aby uświadomić sobie, jak działają notatniki typu Jupyter, stworzymy sobie jeden testowy i pokażemy w nim proste obliczenia oraz wykres.
Tworzenie notatnika
Po stworzeniu projektu klikamy „New notebook” w sekcji Notebooks. Możemy stworzyć pusty lub załadować go z gotowego pliku (który mam lokalnie bądź podając jego URL)
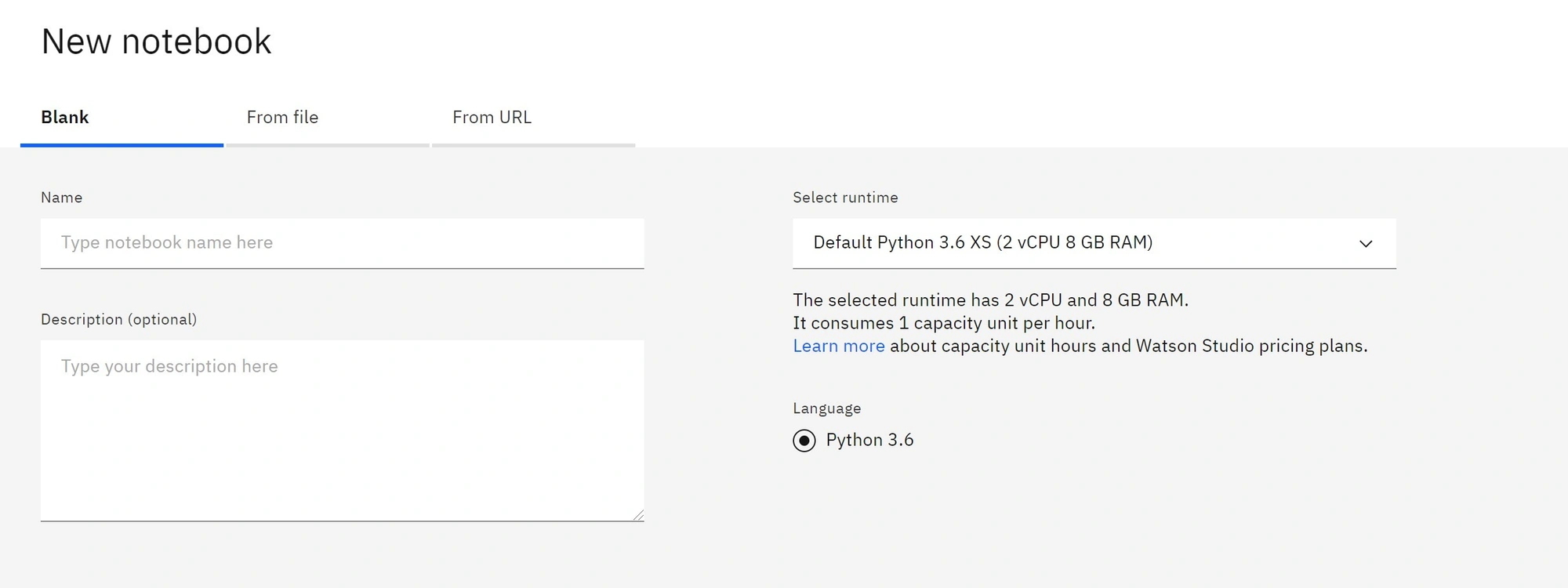
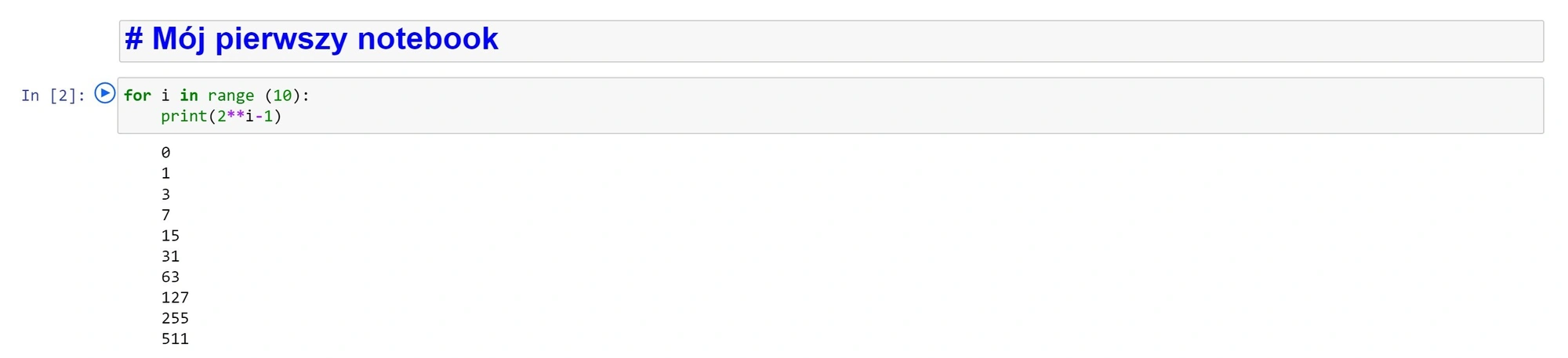
Notatniki łączą funkcję dokumentacji z kodem. Oto przykład nagłówka i prostego kodu wykonanego w Python. Po napisaniu kodu, możemy go uruchomić, wciskając shift-Enter.
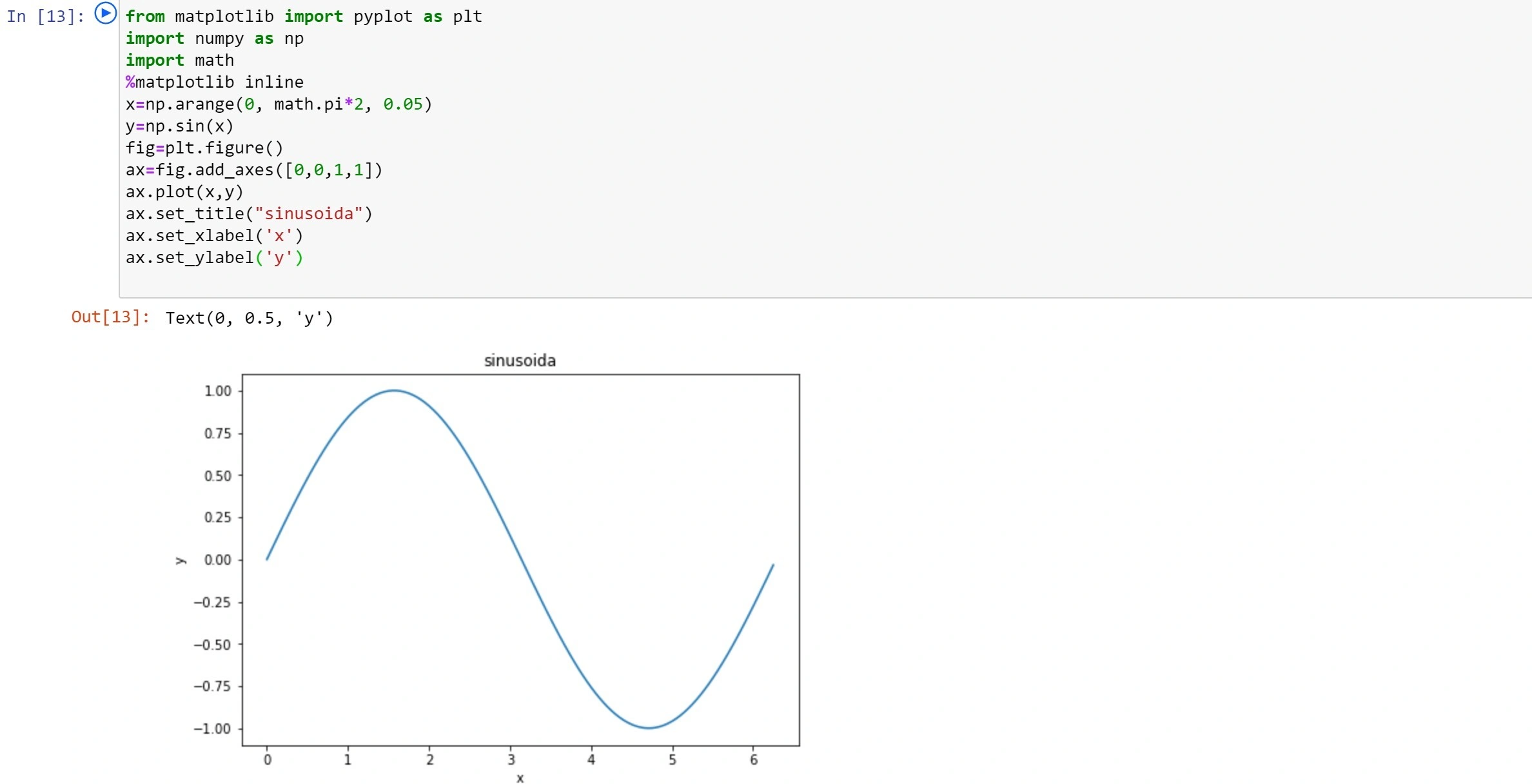
Spróbujmy wykonać coś bardziej złożonego. W tym celu załadujemy zewnętrzne biblioteki pyplot oraz numpy i użyjemy biblioteki Pythona math, aby narysować wykres. Mamy kontrolę nad wyglądem i danymi wykresu z kodu.
Watson Services
Watson Services umożliwiają stworzenie sprofilowanych i predefiniowanych usług typu machine learning, aby następnie wystawić je do użycia w naszej aplikacji. Jest to odmienne podejście od poprzedniego - tutaj nie tylko robimy badania na danych, ale i możemy „ubrać” je w przydatne dla naszej aplikacji rozwiązanie (np. rozpoznające twarze na zdjęciach). Usług z Watson Services możemy też używać w naszych innych projektach oraz notatnikach Jupyter.
Wśród rodzajów Watson Services znajdziemy między innymi
- Analizę treści i wyszukiwanie Cognitive Search)
- Możliwość tłumaczenia tekstów w języku naturalnym (Language Translator)
- Machine Learning (uczenie maszynowe)
- Klasyfikację treści (kategoryzowanie tekstów i obrazów)
- Rozumienie języka naturalnego (np. w celu zamiany na polecenia, które aplikacja może zrozumieć)
- Analizator tonu tekstu (potrafi określić, jak nacechowana jest wypowiedź - pozytywnie, negatywnie czy neutralnie)
- Zamiana mowy na tekst i odwrotnie
- Rozpoznawanie obrazów
- Watson Assistant, któremu wcześniej poświęciliśmy osobny tekst.
Przykład użycia - usługa udostępniona na zewnątrz
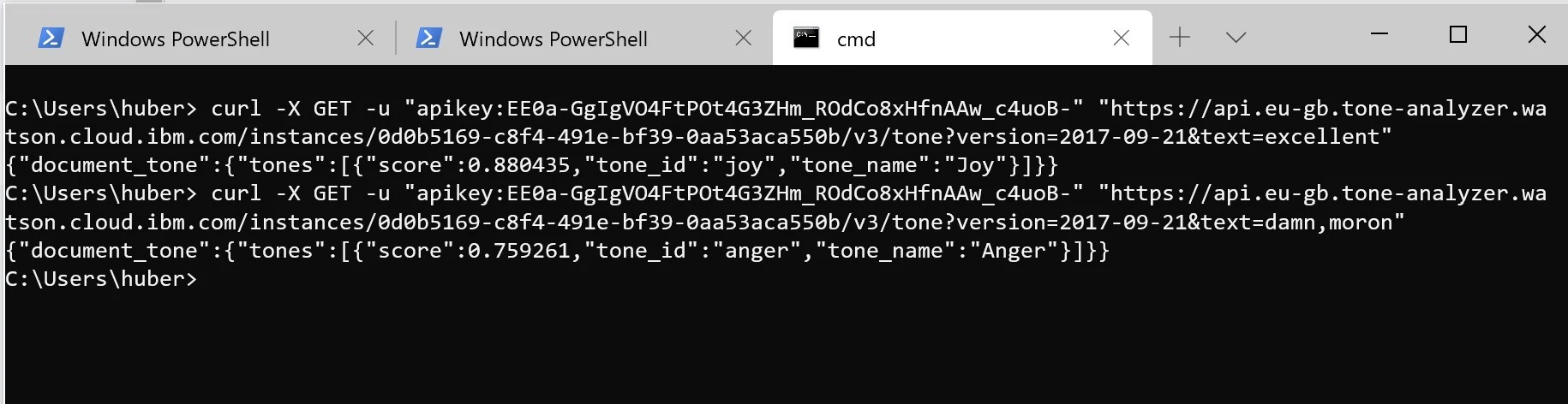
Każda ze stworzonych usług może być, po dodaniu odpowiedniego klucza API, udostępniona na zewnątrz. Oto jak łatwo stworzyć np. analizator tonu tekstu.
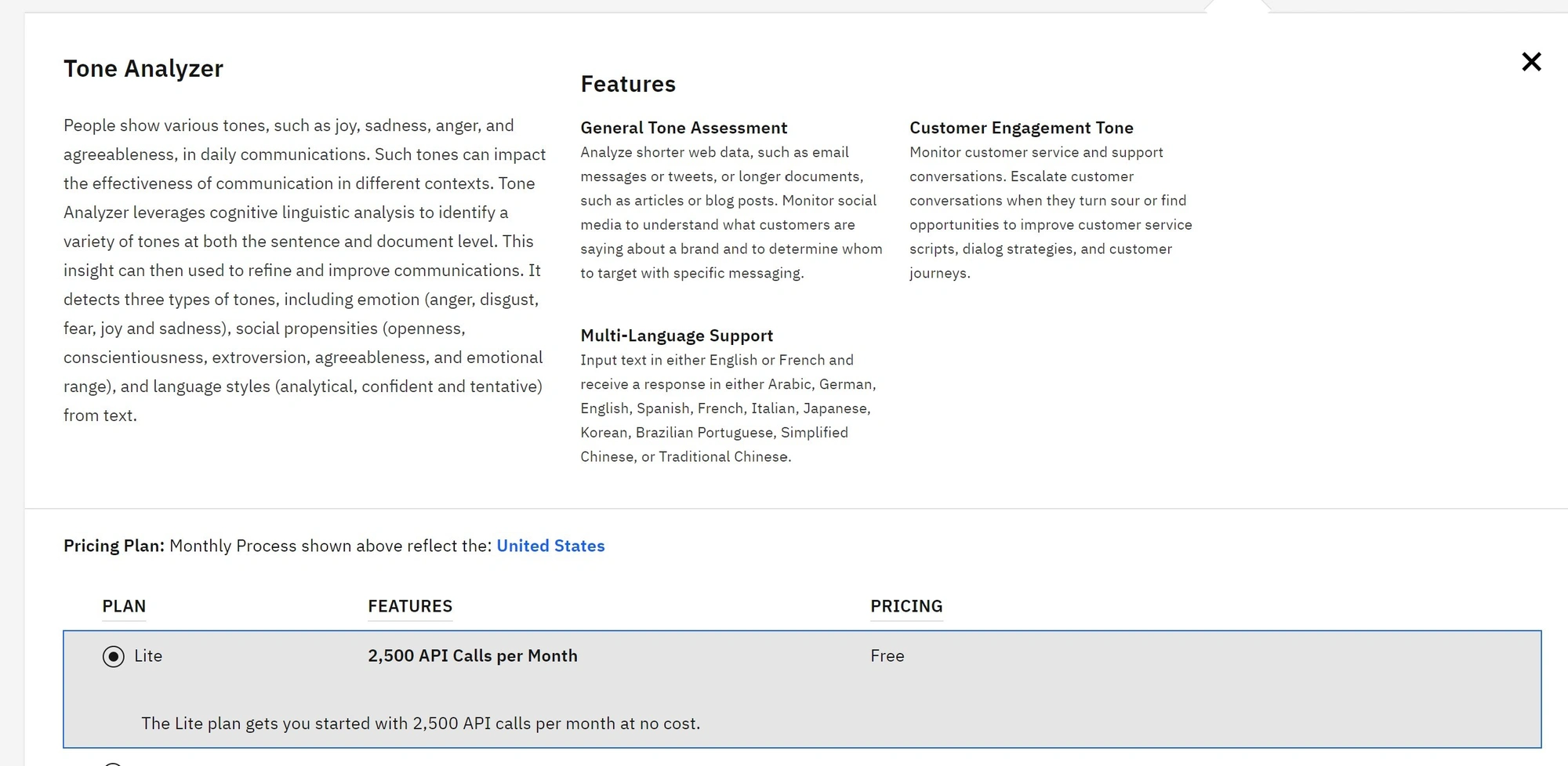
Następnie dodajemy klucz mamy stworzony URL, pod którym możemy odpytywać naszą usługę. Oto dwa przykładowe wywołania (na słowa które kojarzą się pozytywnie i negatywnie, sugerujące złość i radość).
Watson OpenScale
Gdy nasze rozwiązanie oparte na AI znajdzie się w środowisku produkcyjnym, dobrze jest monitorować jego wydajność i skalowanie. Do tego służy Watson Openscale. OpenScale śledzi i mierzy wyniki działania modeli sztucznej inteligencji w całym jej cyklu życia, nadzoruje jej pracę i modyfikuje jej właściwości w zależności od sytuacji biznesowej — bez względu na miejsce utworzenia i działania modelu.
Modele mogą być również badane przed udostępnieniem. OpenScale pozwala przetestować, jak będą się zachowywać w warunkach zwiększonego zapotrzebowania na usługę.
Watson OpenScale pozwala również wykryć nieprawidłowości w działaniu naszej AI, w momencie, kiedy dane z okresu trenowania modelu zmieniły się mocno w stosunku do danych, na których model pracuje. Możliwe jest ustalenie składowych, które najmocniej wpływają na wynik. Można też sprawdzić współczynnik sprawiedliwości (ang. fairness) modelu np. w wyżej wspomnianych modelach przyznających kredyt.
Podsumowując, usługi kryjące się pod nazwą Watson dają użytkownikowi szeroki wachlarz możliwości w zakresie tworzenia najróżniejszych modeli machine learning, dialogów chatbotowych, modeli rozpoznawania obrazów, czy przetwarzania języka naturalnego.
Każdy z serwisów Watson można przetestować za darmo i bez podpinania karty kredytowej i nawet więcej – w ramach darmowego planu Lite możliwe jest zbudowanie wielu ciekawych aplikacji.
Rejestracji możemy dokonać, wchodząc na stronę tworzenia konta i już po kilku minutach możemy rozpocząć pracę nad aplikację używającą AI i machine learning.
* Materiał powstał przy współpracy z IBM.