Zajmujesz się zawodowo danymi? Spodoba ci się Watson Studio
Apple (nie Amazon! - HT) ma swoją Siri, Microsoft ma Cortanę, a IBM postanowił twarzą swoich usług związanych ze sztuczną inteligencją uczynić Watsona.

Wbrew pozorom swojej nazwy Watson nie zawdzięcza bohaterowi opowiadań Arthura Conan Doyle’a o Sherlocku Holmesie. Watson dostał imię po pierwszym prezesie IBM, Thomasie J. Watsonie, który sprawował tę funkcję w latach 1914-1956.
Watson narodził się w 2007 r., gdy IBM Research stworzył własną wersję uczestnika teleturnieju Jeopardy. Jego podstawowa umiejętność potrzebna do uczestnictwa w programie telewizyjnym, czyli umiejętność odpowiadania na pytania zadane w języku naturalnym, rozwinęła się do dziś w całą kolekcję umiejętności, usług i serwisów.
Większość z nich dostępna jest dziś za pomocą IBM Cloud. Tak - tego, co mogliśmy podziwiać na ekranach telewizorów 13 lat temu, dziś możemy użyć za pomocą naszego laptopa podłączonego do sieci.
Watson Studio
Watson to dziś ponad 50 różnych technologii, takich jak uczenie maszynowe, deep learning, analiza obrazów (computer vision), czy rozpoznawanie głosu. IBM woli używać pojęcia cognitive zamiast AI, aby opisać wszystkie umiejętności dostępne za pomocą Watsona.
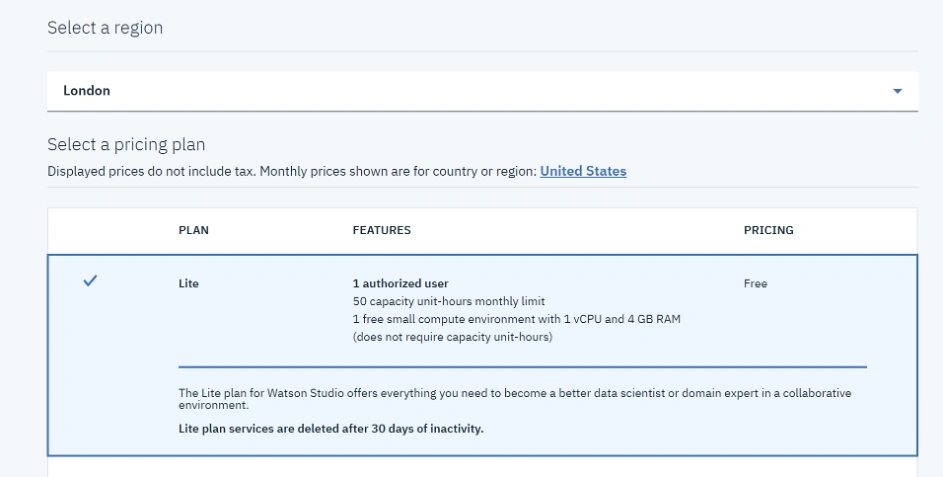
Podobnie jak poprzednio zacznijmy od zalogowania się do panelu zarządzania naszym kontem IBM Cloud. Wybieramy AI z kategorii i klikamy na Watson Studio. Jak widzimy, w darmowym planie mamy aż 50 godzin użytkowych i środowisko z 4 GB RAM.
Już po chwili nasza instancja Watson Studio jest już gotowa.
Kliknijmy więc „Get started” i rozejrzyjmy się, co oferuje nam Watson Studio – narzędzie do tworzenia i uruchamia projektów typu Cognitive. Możemy w nim przygotowywać duże ilości danych (to doskonałe narzędzia dla analityka czy statystyka), przetwarzać je, analizować i budować dla nich modele.
Na początek wykorzystajmy jeden z przykładowych szablonów projektów. To one nadają się najlepiej do nauki tego narzędzia.
Mamy do dyspozycji dwa przykłady: przewidywania zainteresowania klienta w celu zoptymalizowania kampanii reklamowej oraz przewidywania zachowania związanego z zakupami za pomocą Machine Learningu.
Po kilkunastu sekundach mamy otwarty projekt:
Jak widać, jednym z elementów rozwiązania jest projekt w bardzo znanym i lubianym przez data scientists formacie Jupyter.
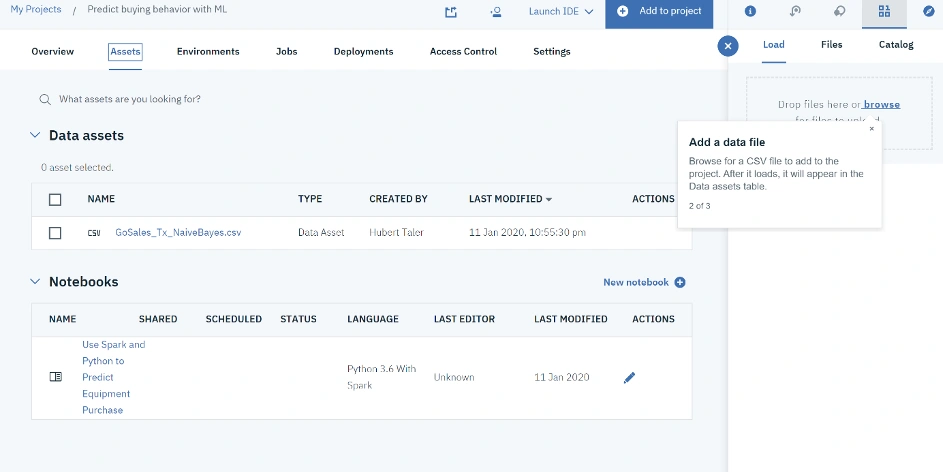
Przykładowe dane, zawarte w pliku CSV, określają preferencje zakupowe – konkretnie łączą fakt zakupów z danej kategorii z wiekiem, płcią, stanem cywilnym oraz stanem zatrudnienia. Ciekawe, co możemy z nich wyciągnąć za pomocą ML.
Ponieważ skorzystaliśmy z projektu przykładowego, uprościliśmy sobie zadanie. Odpowiedni notatnik Jupyter, wykorzystujący Pythona i Spark, został już dla nas przygotowany.
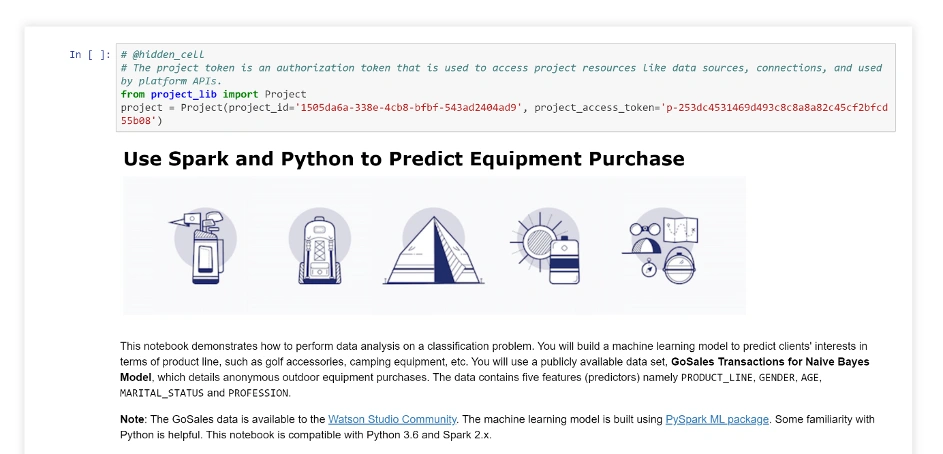
Dzięki niemu możemy się nauczyć, jak załadować dostępne dane, jak dokonać ich ręcznej eksploracji jako bazy danych oraz jak je zwizualizować (tu użyto popularnej biblioteki Pandas):
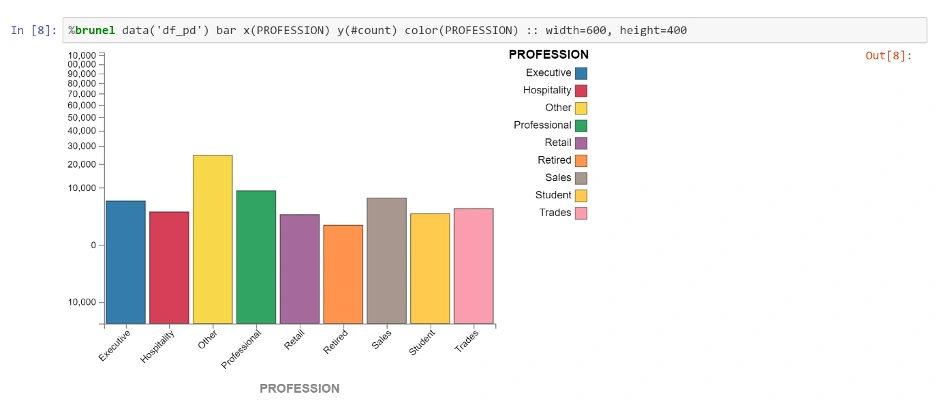
Na sam koniec mamy możliwość zbudowania modelu machine learning. Możemy go poddać treningowi na podstawie danych, tak aby nauczył się przywidywać decyzje zakupowe. Wszystkie polecenia mamy gotowe w notatniku, nic nie stoi jednak na przeszkodzie go edytować.

Dopiero teraz „zużywamy” dostępne nam zasoby – oglądanie statycznego notatnika nie zużywało ich.
W końcu możemy rozwinąć skrzydła: Jupyter to wspaniałe narzędzie dla statystyka. Stworzenie wykresu to jedno polecenie.
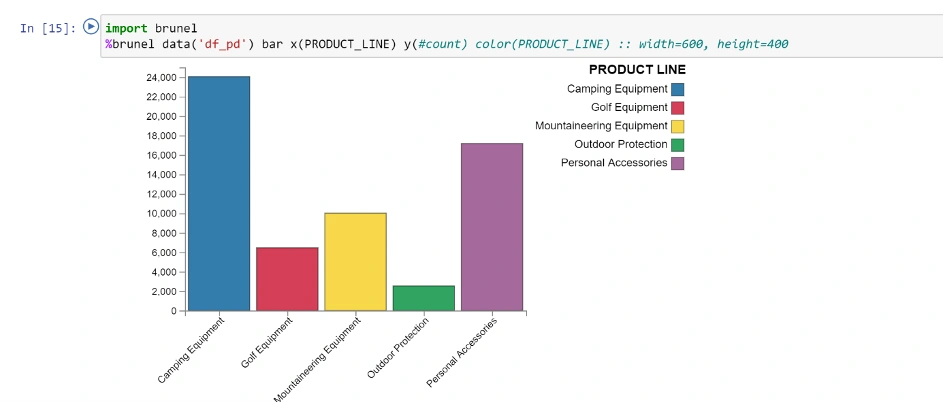
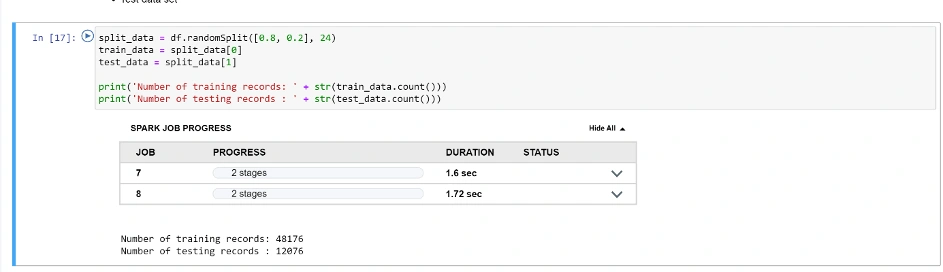
Podzielmy dane na treningowe (używane do uczenia modelu) i testowe (używane do jego weryfikacji i oceny skuteczności):
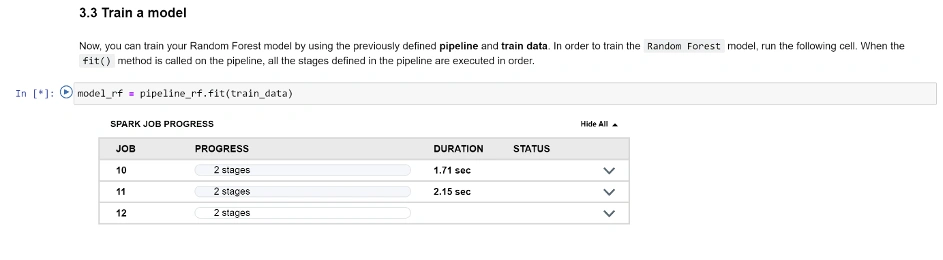
Możemy rozpocząć trening:
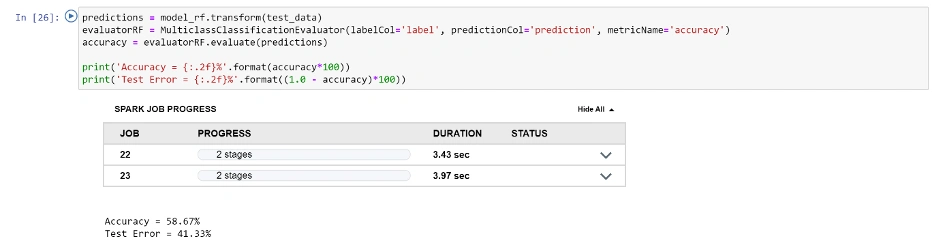
Z fazy testowania wynikło, że skuteczność modelu to trochę ponad 58%. Nie za dobrze, ale w celach edukacyjnych ominiemy dalsze modyfikacje modelu.
Watson Studio to narzędzie, które łączy funkcje zarządzania zasobami (np. plikami z danymi, które możemy przechowywać na obiektach typu storage w IBM Cloud), z dostępem do notatników w Jupyter. Dodatkowo pozwała w łatwy sposób tworzyć i publikować raporty oraz wielokrotnie powtarzać obliczenia dla różnych parametrów. To prawdziwy warsztat pracy naukowca zajmującego się danymi bądź statystyką.