Snapdragon X2 pozamiatał. Używałem go i rozmawiałem z twórcami
Qualcomm zaprosił mnie do swojej siedziby w San Diego by pochwalić się układem, który zawita do przyszłorocznych laptopów, mini PC i tabletów. Firma była tak pewna siebie, że udostępniła mi wszystko. Serio: WSZYSTKO. Ludzi, sprzęt, układy. Dobrze wie, że stworzyła coś wyjątkowego.

Nowa platforma została zaprojektowana od podstaw. W jej sercu kryje się 31 mld tranzystorów wykonanych w procesie TSMC N3, a cała architektura przynosi skok wydajności, który trudno zignorować. Sercem Snapdragona X2 są trzy klastry procesorów Qualcomm Oryon trzeciej generacji. Każdy z nich pełni inną rolę, tworząc razem orkiestrę obliczeniową, w której każdy instrument gra na najwyższym poziomie.
Snapdragon X2 - cechy ogólne
Prime Cores to dwa klastry zaprojektowane z myślą o maksymalnej responsywności. Performance Core to trzeci klaster skupiony na pracy wielowątkowej. Tu wzrost wydajności sięga 50 proc., co czyni go idealnym narzędziem do obróbki wideo, pracy na ogromnych arkuszach kalkulacyjnych czy intensywnej wielozadaniowości.
Czytaj też:
Dual-Core Boost to wisienka na torcie - procesor potrafi osiągnąć 5 GHz w tym trybie, dostarczając dodatkowej mocy dokładnie wtedy, gdy jest najbardziej potrzebna. To wszystko działa w ramach trzech niezależnych klastrów, co pozwala na elastyczne zarządzanie zasobami i energią. Efekt? Wydajność, która nie idzie w parze z drenażem baterii.
Jeśli CPU jest silnikiem, to GPU jest turbiną. W Adreno X2-90 wydajność wzrosła 2,3-krotnie względem poprzednika. A do tego potężne NPU - jeszcze kilka lat temu dedykowane jednostki neuronowe wydawały się egzotyką. Dziś są niezbędne, a Hexagon NPU w Snapdragonie X2 pokazuje, jak daleko zaszliśmy. Wydajność AI wzrosła o 78 proc.

Snapdragon X2 to także ogromne ulepszenia w zarządzaniu pamięcią. 128 GB adresowalnej pojemności i przepustowość 228 GB/s to wzrost o 69 proc. względem poprzednika. 192-bitowa przepustowość zintegrowanej pamięci pozwala osiągnąć prędkości do 9523 MT/s a cache LLC o pojemności 9 MB z 70 proc. większą przepustowością to rozwiązanie dotąd zarezerwowane dla desktopów.
Całość spina Custom Spine Coherent Fabric - niestandardowa magistrala, która łączy CPU, GPU, NPU i Sensing Hub. Efekt? Minimalne opóźnienia i zoptymalizowany pobór energii.

W kwestii łączności Snapdragon X2 nie pozostawia żadnych kompromisów. Snapdragon X75 5G Modem oferuje pobieranie do 10 Gbps i wysyłanie do 3,5 Gbps. FastConnect 7800 wprowadza Wi-Fi 7 z prędkościami do 5,8 Gbps i opóźnieniami na poziomie 2 ms. Jednoczesne połączenia dzięki Wi-Fi High Band Simultaneous (HBS), podwójny Bluetooth, obsługa LE Audio i Snapdragon Sound Technology Suite to ostatnie wisienki na tym kawałku tortu.
Snapdragon X2 nie oszczędza też na transferach danych. Obsługuje USB4 z 40 Gbps, trzy porty USB-C 5.0 x12 i PCIe 4.0 x4, a także NVMe via PCIe 5.0 dla najszybszych SSD oraz UFS 4.0, SD Express i UHS-I.
Qualcomm nie zapomniał o tym, co dziś równie ważne jak wydajność - o bezpieczeństwie. Producent chwalił się Secure Processing Unit (SPU) nowej generacji, Trust Management Engine i ulepszoną ochrona pamięci. Integracja z Microsoft Pluton dodatkowo wzmacnia bezpieczeństwo, a oprócz tego Qualcomm zapewnia technologię zdalnego blokowania, wymazywania, lokalizowania i diagnozowania urządzenia - niezależnie od miejsca na świecie, w którym aktualnie urządzenie się znajduje.
Specyfikację uzupełniają Spectra ISP, Adreno VPU dual-core z 2,5-krotnym wzrostem wydajności kodowania, Sensing Hub z mikro-NPU i DSP do rozpoznawanie obrazu i dźwięku w czasie rzeczywistym, Custom Power Grid optymalizujący pobór mocy dla każdego komponentu i mechanizm Quick Charge 5+ pozwalający naładować urządzenie w kilka minut, a nie godzin.

Po pierwsze, procesor. Oryon Gen 3 to ważne ostrzeżenie dla Intela, AMD i… Apple’a
Mamy do czynienia z procesorem, który oferuje 39 proc. wyższą wydajność niż poprzednia generacja, a jednocześnie zużywa 43 proc. mniej energii. Qualcomm zerwał z podziałem na jeden typ rdzeni wydajnościowych. Snapdragon X2 korzysta z układu trzech klastrów: dwóch Prime i jednego Performance. Ta triada pozwala połączyć dwa światy - bezwzględną moc obliczeniową i oszczędność energii.
Każdy z dwóch klastrów Prime zawiera sześć rdzeni, wspieranych przez 16 MB pamięci L2. Bazowa częstotliwość to 4,4 GHz, ale w trybie turbo układ osiąga imponujące 5,0 GHz. To oznacza, że nawet najbardziej wymagające zadania - od renderowania grafiki po intensywne obliczenia - nie stanowią dla niego problemu.

Na tym jednak nie koniec. Każdy klaster Prime wyposażono w Qualcomm Matrix Engine - akcelerator macierzowy, który integruje obliczenia sztucznej inteligencji bezpośrednio z CPU. Dzięki temu operacje ML nie muszą konkurować o zasoby, a system działa płynniej. Do tego dochodzą usprawnienia w predykcji gałęzi, operacjach Load-Store i prefetchingu - niewidoczne dla użytkownika, ale kluczowe dla responsywności.
Trzeci klaster to sześć rdzeni Performance z 12 MB pamięci L2. Ich bazowa częstotliwość wynosi 3,6 GHz. Są zoptymalizowane pod kątem pracy poniżej 2 W, co czyni je idealnymi do zadań codziennych - przeglądania Internetu, streamingu czy obsługi komunikatorów. Choć są mniej wydajne niż rdzenie Prime to zachowują architekturę out-of-order, więc nie są kompromisem technologicznym. To raczej świadome zbalansowanie mocy i efektywności.


Największym wyróżnikiem rdzeni Prime jest szerokie okno dekodowania. Procesor może wysłać aż 9 mikrooperacji na cykl do sekcji wykonawczej. To rozwiązanie, które pozwala utrzymać równowagę między złożonością a efektywnością.
Instrukcje trafiają do L1 Instruction Cache o pojemności 192 KB, zorganizowanej w 6-drożnym układzie. Procesor pobiera 16 instrukcji na cykl, wspierany przez L1 ITLB z 256 wejściami. Predykcja gałęzi jest tu niezwykle zaawansowana: 1-cyklowy BTB, 2-cyklowy predyktor warunkowy i predyktor celu pośredniego. Nawet jeśli predykcja zawiedzie to narzut wynosi 13 cykli, co dzięki mechanizmom kompensacji nie spowalnia pracy systemu. Dekoder obsługuje do 9 instrukcji na cykl, w tym złożone operacje z wielu mikroinstrukcji. To zapewnia nieprzerwany przepływ danych.
Procesor obsługuje 9 operacji na cykl w fazie zmiany nazw rejestrów. Do dyspozycji ma ponad 400 rejestrów całkowitoliczbowych i tyle samo wektorowych. Dzięki temu może przechowywać ogromną liczbę danych pośrednich bez konieczności sięgania do pamięci. Reorder Buffer liczy ponad 650 wejść, co pozwala na wydajne wykonywanie instrukcji out-of-order. Qualcomm zastosował też fuzję instrukcji i rozstrzyganie niejednoznaczności pamięci pamięci, co dodatkowo zwiększa przepustowość.

Sekcja całkowitoliczbowa dysponuje 6 szerokimi ścieżkami 64-bitowymi, każda z 20 stacjami rezerwowymi. Procesor może wykonywać jednocześnie:
- 6 operacji ALU,
- 4 instrukcje skok,
- 2 operacje mnożenia/akumulacji.
Opóźnienia są minimalne - pojedynczy cykl dla ALU i skoków, trzy cykle dla mnożenia. Obsługiwane są także operacje dzielenia, kryptograficzne (CRC) i autentykacja wskaźników.
Rdzeń Prime posiada cztery 128-bitowe ścieżki wektorowe, każdy z 48 stacjami rezerwowymi. Obsługują operacje FP16, FP32, FP64 oraz BF16 - format popularny w uczeniu maszynowym. Obsługiwane są rozszerzenia kryptograficzne (AES, SHA, PMULL) i ML (Matrix-Multiply), zintegrowane bezpośrednio w ścieżce. Predykacja na poziomie SIMD pozwala na precyzyjne sterowanie wykonaniem.
Jednostka Load-Store obsługuje do 4 operacji na cykl, z pełnym forwardingiem ze store do load. Kolejki liczą 192 wejścia dla load i 56 dla store, a całość wspiera 96 KB L1 Data Cache. Prefetching działa na wielu poziomach - linie przylegające, wskaźniki, tablice, wzorce - zarówno dla cache, jak i TLB. Efekt? Procesor niemal nigdy nie czeka na dane.
Memory Management Unit obsługuje translację dla stron 4 KB, 64 KB, 2 MB, 32 MB, a nawet 1 GB. A do tego pełna wirtualizacja jest pełna, z obsługą translacji dwustopniowej i zagnieżdżonej. L1 TLB dla instrukcji i danych ma po 256 wejść, a L2 TLB aż 8000. Sprzętowy przechód po tabelach stron (in-flight table-walks requests) obsługuje 16 równoczesnych żądań, a pamięć podręczna przechodu buforuje pośrednie węzły, przyspieszając kolejne translacje.
Jednym z najbardziej imponujących elementów Snapdragona X2 Elite jest jego hierarchia pamięci. Dwa klastry Prime otrzymały po 16 MB L2 cache, a klaster Performance - 12 MB. Łącznie daje to aż 44 MB spójnej pamięci podręcznej drugiego poziomu. To wynik, który w świecie mobilnych procesorów robi ogromne wrażenie.

Każdy L2 cache działa synchronicznie z częstotliwością procesora, korzysta z protokołu MOESI i jest inkluzywny wobec pamięci L1. Przepustowość wynosi 64 bajty dla nowych linii, kopii zwrotnych i ofiar (victims), co przekłada się na szybki przepływ danych między L2 a pamięcią główną.
System obsługuje ponad 220 równoczesnych transakcji, a każdy rdzeń może utrzymywać 50+ zawieszonych żądań. Średnie opóźnienie dla scenariusza L1-miss-L2-hit to około 21 cykli - wynik, który w praktyce oznacza płynne działanie nawet przy intensywnym obciążeniu. Qualcomm wprowadził też mechanizmy izolacji wydajności poprzez partycjonowanie i monitorowanie użycia wątków, co pozwala systemowi operacyjnemu lepiej zarządzać wieloma aplikacjami jednocześnie.
Każdy klaster Prime wyposażono w dedykowaną instancję Qualcomm Matrix Engine - akcelerator obliczeń macierzowych, który działa równolegle dla wszystkich rdzeni.
- Podstawą są operacje 64-bitowego mnożenia-akumulacji (MLA) w konfiguracji 8x8 lub 4x8, co zapewnia elastyczność w zadaniach ML.
- Rejestry o długości 512 bitów wspierają formaty BF16, FP16, FP32 oraz INT8, INT16, INT32.
- Engine komunikuje się z pamięcią poprzez 64-bajtowe odczyty i zapisy do L2 cache, co gwarantuje szybki dostęp do dużych wolumenów danych.
- Całość działa w dedykowanej domenie zegarowej, co pozwala niezależnie zarządzać mocą i temperaturą, bez wpływu na główny zegar CPU.
To rozwiązanie sprawia, że Snapdragon X2 jest gotowy na najbardziej wymagające obliczenia związane ze sztuczną inteligencją - od uczenia maszynowego po zaawansowane algorytmy predykcyjne.
Qualcomm nie zapomniał o tym, co dziś równie ważne jak wydajność - o bezpieczeństwie. Snapdragon X2 Elite integruje zestaw funkcji ochronnych bezpośrednio w architekturze rdzenia:
- TrustZone i Secure EL2 zapewniają izolację środowisk i dodatkową warstwę wirtualizacji bezpieczeństwa.
- Rozszerzenia kryptograficzne wbudowane w jednostkę wektorową umożliwiają szybkie szyfrowanie i haszowanie.
- Autentykacja wskaźników i Branch Target ID chronią przed manipulacją przepływem sterowania.
- Specjalne bariery spekulacji oraz instrukcje RCTX zabezpieczają przed atakami typu Spectre, Meltdown, PACMAN, Straight-Line Speculation, Augury.
- Dedykowany generator liczb losowych wspiera operacje kryptograficzne, a szyfry blokowe w strukturach predyktywnych zapewniają dodatkowe zabezpieczenie danych.
- Memory Tagging umożliwia wykrywanie błędów typu Use-after-Free czy Out-of-bounds, działając na zasadzie zamka i klucza dla pamięci.
To zestaw zabezpieczeń, który sprawia, że Snapdragon X2 jest nie tylko szybki, ale i odporny na najpopularniejsze ataki ostatnich lat.
Rdzenie Performance zachowują architekturę out-of-order, ale są mniej szerokie i posiadają uproszczone ścieżki wykonawcze. Mają mniejsze pamięci podręczne i TLB oraz płytsze okno wykonywania instrukcji. Dzięki temu pracują poniżej 2 W, co czyni je idealnymi do codziennych zadań - od przeglądania Internetu po streamowanie multimediów - bez nadmiernego obciążania baterii.
Adreno X2. Poprzedni Snapdragon X nie miał najlepszego układu graficznego
Jednostka graficzna Adreno X2 została rozbudowana do czterech slajsów renderujących, z których każdy posiada własny, kompletny potok przetwarzania grafiki: od wierzchołków, przez rasteryzację, aż po cieniowanie. Efekt? Masowa paralelizacja zadań renderujących, kluczowa dla gier z najbardziej zaawansowaną grafiką.
W sercu każdego slajsu pracują skalarne procesory (SP), wspierane przez mikroprocesory (µSP) odpowiedzialne za instrukcje warunkowe i bardziej złożone operacje. Całość uzupełniają Rozszerzone Jednostki Funkcji (EFUS), które obsługują specjalistyczne obliczenia matematyczne. To architektura, która nie tylko zwiększa moc, ale też inteligentnie rozdziela zadania, minimalizując opóźnienia dzięki lokalnym buforom pamięci.

Największą nowością jest jednak dedykowana jednostka ray tracingu (RTU) w każdym slajsie. Wspierana przez Tree Traversal Unit (TTU) odpowiada za operacje typowe dla ray tracingu - od rozpakowania danych geometrycznych, przez obliczanie przecięć promieni, aż po przechodzenie hierarchicznych struktur przestrzennych.
System pamięci - fundament wydajności
Wydajność GPU to nie tylko liczba procesorów, ale przede wszystkim dostęp do danych. Dlatego Qualcomm stworzył Adreno High-Performance Memory (AHPM) - wbudowaną pamięć SRAM o pojemności 21 MB, zdolną przechowywać kompletne ramki w rozdzielczości QHD+. Każdy slajs ma do dyspozycji 5,25 MB, co znacząco ogranicza konieczność sięgania po wolniejszą pamięć główną.
Przepustowość do procesorów cieniujących sięga 4 TB/s - liczba, która robi wrażenie nawet w świecie desktopów. To oznacza, że GPU może przesłać równowartość dwóch pełnych filmów HD w każdej sekundzie. AHPM wspiera bezpośrednie renderowanie, teselację, przechowywanie wag, a także obliczenia AI.
Dodatkowo zastosowano Uniwersalną Kompresję Przepustowości (UBWC) - bezstratną kompresję danych, która zmniejsza wymagania energetyczne i ogranicza transfery między pamięcią a procesorami.
Geometria - cztery razy szybciej
Jednym z tradycyjnych wąskich gardeł GPU jest przetwarzanie geometrii. Adreno X2 rozwiązuje ten problem oferując do czterech razy szybsze prędkości primitywów niż poprzednia generacja.
Każdy slajs renderujący posiada własne cache dla danych geometrycznych, co eliminuje konflikty w dostępie do pamięci. Ulepszony potok tessellacji i rasteryzacji pozwala obsługiwać modele z tysiącami wielokątów bez spadku wydajności. Efekt widać w grach takich jak Kingdom Come: Deliverance 2 czy Star Wars Outlaws, gdzie bogata geometria otoczenia nie stanowi już problemu.
Ray Tracing - akceleracja sprzętowa
Ray tracing to technika, która nadaje obrazom realizmu poprzez naturalne odbicia, cienie i refrakcje świetlne. Adreno X2 dodaje dedykowane RTU do każdego slajsu.

RTU wspiera zarówno Microsoft DXR 1.1, jak i Vulkan Ray Pipeline, co zapewnia pełną kompatybilność z nowoczesnymi grami. Wewnętrzna architektura obejmuje moduły Fetch, Decompress, Intersection i TTU. Dzięki temu GPU może przetwarzać miliardy promieni światła bez obciążania głównych procesorów. W praktyce oznacza to płynniejszy ray tracing niż w konkurencyjnych rozwiązaniach software’owych.
Technologie graficzne i API
Adreno X2 Elite wspiera pełen zestaw nowoczesnych technologii:
- DirectX 12.2 Ultimate i Shader Model 6.8 - pełna kompatybilność z najnowszymi grami.
- Variable Rate Shading (VRS) - inteligentne oszczędzanie mocy poprzez redukcję pikseli w mniej istotnych obszarach.
- Mesh Shading - generowanie i modyfikacja geometrii bez udziału CPU.
- Sampler Feedback - śledzenie używanych tekstur i ładowanie tylko niezbędnych danych.
Wydajność w praktyce
Testy mówią same za siebie. W benchmarku 3DMark Time Spy Graphics Adreno X2-85 osiągnął 70 proc. wyższą wydajność niż Adreno X1-85 przy tej samej mocy, a efektywność energetyczna wzrosła o 125 proc. Średnio Adreno X2 oferuje 2,3x wzrost FPS względem poprzednika. Jeszcze ciekawsze są porównania z konkurencją desktopową - w grach takich jak Metro Exodus Enhanced Edition czy Borderlands 3 procesor Adreno X2 Elite Extreme osiąga +50 proc. wyższą wydajność niż Intel Core Ultra 9 288V i +29 proc. wyższą niż AMD Ryzen AI 9 HX 370.
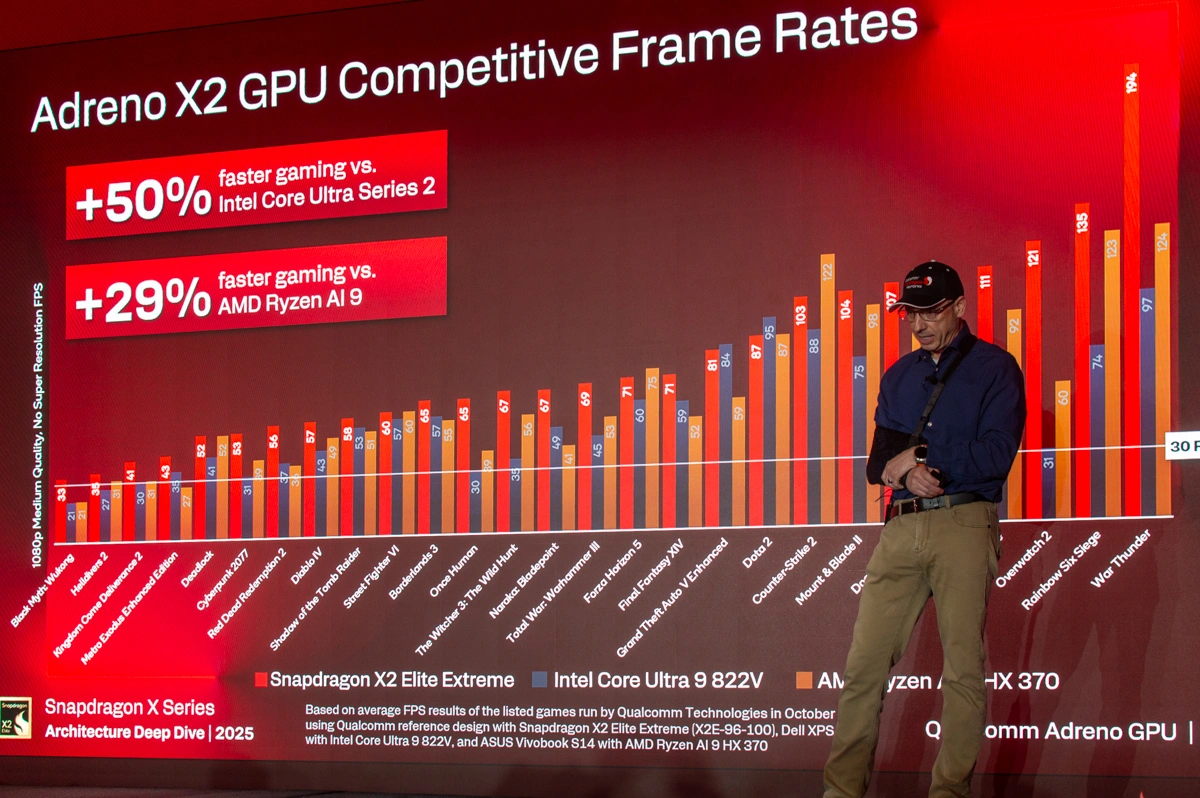
Adreno X2 to nie tylko maszyna do gier. Dzięki implementacji Adreno GPGPU obsługuje obliczenia ogólnego przeznaczenia, wspierając DirectX 12.2 Ultimate, Vulkan 1.4, OpenCL 3.0 i SYCL. GPU obsługuje format BF16 (Brain Float 16), zoptymalizowany dla AI. To oznacza, że może efektywnie wykonywać operacje uczenia maszynowego i wnioskowania - od transkrypcji głosu, przez przetwarzanie obrazu, aż po tłumaczenia w czasie rzeczywistym. Dodatkowe mechanizmy, takie jak Local Memory Broadcast i General Shuffles pozwalają procesorom współpracować bez konieczności sięgania do globalnej pamięci, co redukuje opóźnienia i zużycie energii.
Planowanie pracy i optymalizacja
Qualcomm wprowadził ulepszone planowanie pracy (Work Scheduling). GPU obsługuje wave size 64-wide, czyli 64 instrukcje równolegle w jednej fali obliczeń. Każdy µSP posiada 128 KB pamięci rejestrów GPR, co pozwala przechowywać znaczną ilość danych lokalnych. Najciekawszą nowością jest dual-issue 64-wide workgroups per µSP - możliwość wydania dwóch niezależnych grup poleceń po 64 instrukcje każda. To rozwiązanie eliminuje wąskie gardła związane z małymi draw calls, które są szczególnie intensywnie wykorzystywane w grach tworzonych na Unreal Engine 5.
Surowa moc GPU to jedno, ale dostęp do właściwych narzędzi i sterowników to coś zupełnie innego. Qualcomm zaprezentował Snapdragon Control Panel - aplikację towarzyszącą dla GPU Adreno, która aktualizuje sterowniki grafiki na bieżąco i automatycznie optymalizuje ustawienia gier. Aplikacja zawiera katalog ponad 73 gier i aplikacji zoptymalizowanych dla Snapdragonów X, z regularnymi aktualizacjami wydajności i poprawkami błędów.

Wsparcie dla gier jest zaskakująco szerokie. Qualcomm potwierdził, że ponad 90 proc. najpopularniejszych tytułów gier jest grywalnych w momencie uruchomienia na Snapdragon X2. Dodatkowo GPU osiągnął certyfikowaną kompatybilność dla tysięcy gier i aplikacji Windows. Szczególnie ważne dla graczy zainteresowanych fair play jest obsługa i zgodność z kernel-level anti-cheat, w tym Epic Games Online Services, Tencent ACE Anti Cheat, Roblox, Denuvo by Irdeto, InProtect GameGuard, BattleEye i Uncheater. To oznacza, że gracze na Snapdragonie X2 mogą uczestniczyć w grach kompetytywnych bez obaw o problemy z systemami antycheatowymi.
Efektywność energetyczna: gra o baterie
W ostatecznym rozrachunku dla mobilnych urządzeń energooszczędność to niezbędna cecha. Adreno X2 oferuje 125 proc. lepszą wydajność na wat niż poprzedni Adreno X1 - co oznacza, że GPU może wykonać dwa i pół razy więcej pracy zużywając tę samą ilość energii.
Ta efektywność jest możliwa dzięki kilku czynnikom: zaawansowanej architekturze pamięci (AHPM i UBWC), specjalizowanym jednostkom (RTU dla ray tracingu) oraz starannym optymalizacjom w potoku przetwarzania. Dla użytkownika to oznacza: dłuższy czas pracy na baterii nawet przy zaawansowanej grafice i mniejsze nagrzewanie się urządzenia.

Sztuczna inteligencja i NPU
Rok 2024 zapisał się w historii jako moment przełomowy dla sztucznej inteligencji na komputerach. Snapdragon X2 to układ, który nie tylko podnosi poprzeczkę, ale wręcz zmienia reguły gry. Dzięki zmodernizowanemu procesorowi Hexagon NPU oferuje 78 proc. wzrostu wydajności względem poprzedniej generacji i osiąga aż 80 TOPS (teraoperacji na sekundę).
W praktyce oznacza to, że mamy do czynienia z najszybszym NPU w laptopach. Wyniki testów są wręcz porażające: 4151 punktów w Procyon AI Computer Vision Score, czyli 5,7 razy więcej niż Intel Core Ultra 9 285H. Jeszcze bardziej imponujące jest to, że Qualcomm osiągnął tę wydajność przy zachowaniu niezwykłej efektywności energetycznej.
Hexagon NPU - jak jest zbudowany?
Tradycyjne NPU koncentrowały się na obliczeniach macierzowych. Qualcomm poszedł dalej, stawiając na zrównoważenie mocy pomiędzy czterema filarami:
- przetwarzaniem skalarnym,
- wektorowym,
- macierzowym,
- oraz przepustowością magistrali pamięci (DMA).
W efekcie pracować równocześnie może nawet 200 wątków na jednym rdzeniu skalarnym, redukując opóźnienia operacyjne. Skalarna jednostka przetwarzająca została przeprojektowana od podstaw. Obsługuje teraz Simultaneous Multi-Threading na 6 wątkach per zespół, a każdy wątek wykonuje 4-szerokie instrukcje VLIW. Rezultat? 143 proc. wzrost przepustowości skalarnej i 127 proc. wzrost przepustowości magistrali.

Sekcja wektorowa również przeszła transformację. Osiem równoległych silników obsługuje operacje SIMD 128-bajtowe, a przepustowość wzrosła o 143 proc. względem poprzednika. Co ważne, dodano obsługę nowych formatów danych - FP8 i BF16 - kluczowych dla nowoczesnych modeli AI, które wymagają kompromisu między precyzją a wydajnością.
Przyspieszacz macierzowy zyskał 78 proc. większą przepustowość i obsługę 2-bitowych wag, co otwiera drogę do ekstremalnej kompresji modeli. Sprzętowo wspiera teraz złożone operacje, takie jak fused activation functions czy depthwise convolution, eliminując kolejne wąskie gardła. Dedykowane cache dla wag i aktywacji oraz osobna szyna zasilająca sprawiają, że obliczenia macierzowe działają z maksymalną efektywnością.

Qualcomm zadbał, by moc NPU była łatwo dostępna. AI Stack wspiera TensorFlow Lite, PyTorch i ONNX, a ONNX Runtime integruje CPU, GPU i NPU. Deweloperzy mogą wdrażać modele open-source bez głębokich zmian.
Qualcomm wyróżnia trzy filary obliczeń AI:
- CPU - szybka odpowiedź i małe modele (OCR, Windows Hello).
- GPU - wysokowydajne przetwarzanie pikseli i shadera, idealne dla grafiki.
- NPU - serce sztucznej inteligencji, zoptymalizowane dla dużych modeli neuronowych i agentic AI.
Snapdragon X2 osiąga 3,8 razy lepszy wynik na wat niż Intel Core Ultra 9 285H. Dzięki obsłudze formatów od FP16 po FP4 modele mogą uzyskać nawet 4-krotny wzrost TOPS przy użyciu INT8 i W4A16. Rezultat? 1,6-krotna poprawa wydajności przy tej samej mocy (5 W) względem poprzedniej generacji.

Snapdragon X2 NPU obsługuje już ponad 1000 modeli i 300 aplikacji. Windows AI Stack zapewnia integrację z Hugging Face, Windows ML oraz wsparcie dla PyTorch i TensorFlow poprzez ExecuTorch Runtime.
Snapdragon X2 w praktyce. Chrzanić Qualcomma - siadam do laptopa przyszłości i testuję



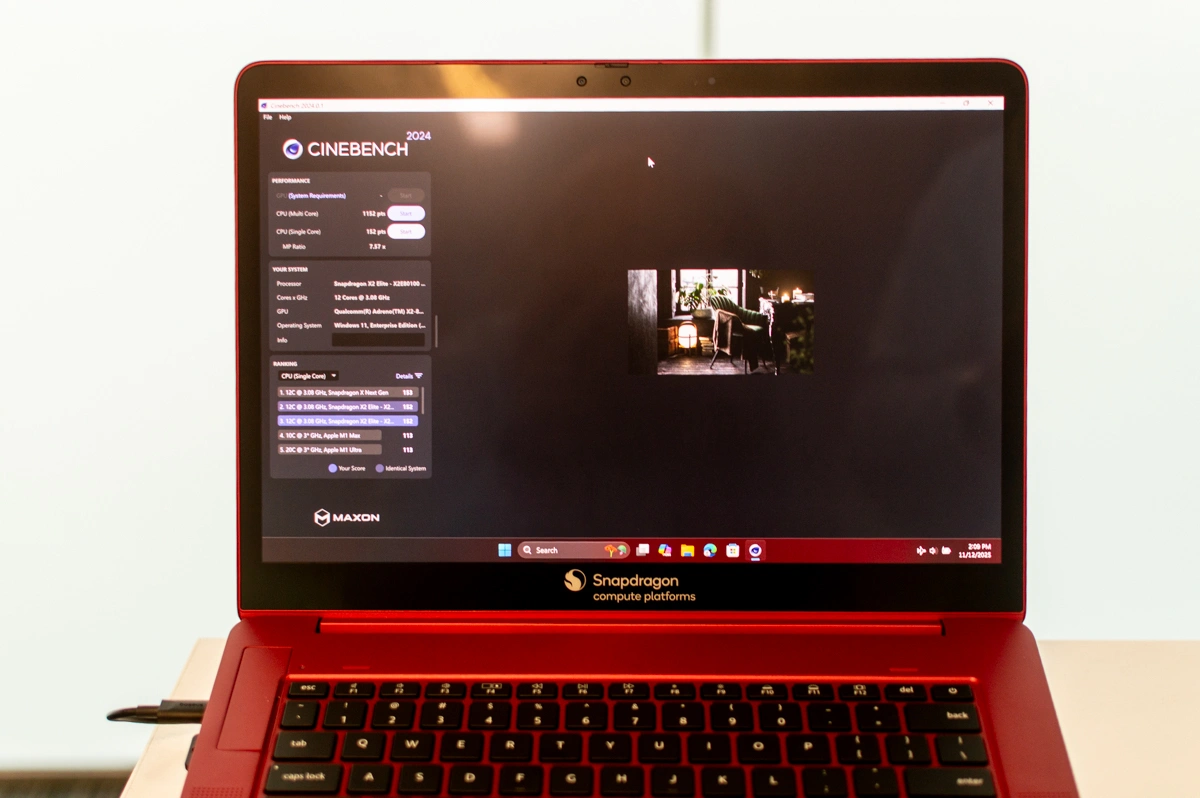
Producenci procesorów często podają liczby, które nie oddają rzeczywistości. Tradycyjnie mierzy się moc na poziomie samego SoC-a, ignorując pamięć RAM, kontrolery czy układy zasilania. Qualcomm postanowił to zmienić, wprowadzając metodologię INPP (Idle-Normalized Platform Power).
INPP mierzy całkowitą moc platformy, odejmując minimalny pobór energii w stanie bezczynności. To oznacza, że wyniki pokazują faktyczne zużycie energii przez cały system - procesor, pamięć, kontrolery i zasilacze. W praktyce daje to obraz tego, co naprawdę dzieje się w porcie USB-C twojego laptopa. Pomiar odbywa się w rygorystycznych warunkach: ekran przy minimalnej jasności, brak aktywnych aplikacji, wyłączona łączność.

Architektura Oryon wprowadza Cluster-Level Multi-Level Boost - mechanizm, który pozwala każdemu klastrowi niezależnie regulować taktowanie:
- 1 rdzeń aktywny: 5,0 GHz
- 2 rdzenie: 4,8 GHz
- 3 rdzenie: 4,47 GHz
- 4-6 rdzeni: 4,45 GHz
To rozwiązanie pozwala zachować responsywność przy lekkim obciążeniu, a jednocześnie kontrolować temperaturę i pobór mocy przy pracy wielowątkowej. Drugą innowacją jest Scenario-Based Optimization (SBO) - oprogramowanie, które monitoruje, co robisz na laptopie, i dynamicznie dostosowuje konfigurację. Odtwarzasz wideo? System obniża pobór mocy. Grasz? Priorytetem staje się wydajność.
To co z tym zużyciem energii? Testy zostały przeprowadzone na Snapdragonie X2 Elite Extreme (X2E-96-100). Wyniki pokazują, jak różne obciążenia wpływają na zużycie energii:
- Geekbench v6 MT: 8,41 W INPP
- Cinebench R24 MT: 70,31 W INPP
- Memory Test: 107,94 W INPP
- Handbrake (wideo): 84,78 W INPP
- Integer Spinloop: 30,19 W INPP
Różnice są ogromne, ale to właśnie pokazuje jak elastycznie procesor zarządza mocą. Geekbench jest bardziej zrównoważony, Cinebench i Memory Test wyciskają maksimum z układu, a Integer Spinloop pokazuje minimalny pobór przy wysokim taktowaniu.

Największe wyzwanie dla projektantów laptopów to temperatura obudowy. Nikt nie chce trzymać na kolanach urządzenia rozgrzanego do 100°C. Dlatego wprowadzono limity Tskin - maksymalnej temperatury obudowy. W testach Cinebench MT przy limicie 50°C Snapdragon X2 Elite osiągnął maksymalnie 53,2°C na tylnej obudowie, przy temperaturze otoczenia 23,9°C. Podczas 30-minutowego testu temperatura początkowa wynosiła 54°C, a później systematycznie spadała do około 30°C. To dowód, że regulacja termiczna działa skutecznie i stabilnie.
Snapdragon X2 korzysta z dwóch limitów mocy:
- SOC PL1 - limit utrzymania mocy, związany z Tskin.
- SOC PL2 - limit chwilowego wybuchu mocy.
W testach Cinebench MT procesor startował z taktowaniem bliskim 4.0 GHz, a następnie stopniowo je obniżał, aby utrzymać limity. Maksymalne temperatury poszczególnych komponentów wyglądały następująco:
- Rdzenie nieaktywne: 85,7°C
- L1 cache: 96,5°C
- L2 cache: 94,6°C
- GPU: 73,6°C
- Network processor: 79,9°C
Najważniejsze dla użytkowników laptopów: co dzieje się po odłączeniu zasilacza? Snapdragon X2 zachowuje od 85,6 proc. do 100 proc. wydajności w zależności od testu.
- Geekbench v6.5 ST: 100 proc.
- Geekbench v6.5 MT: 98,9 proc.
- Cinebench R24 ST: 100 proc.
- Cinebench R24 MT: 99,3 proc.
- Speedometer 3.1: 100 proc.
- Procyon Office: 99,6 proc.
Jedynie w teście Geekbench AI wynik spadł do 85,6 proc. - co wynika z bardziej agresywnego limitowania NPU. To rozsądne, bo jednostka AI jest jednym z największych konsumentów energii.

Jednym z najważniejszych punktów, które Qualcomm podkreśla przy Snapdragonie X2, jest jego elastyczność projektowa. Układ został zaprojektowany tak, aby działać w szerokim zakresie mocy - od 5 W w telefonach z chłodzeniem pasywnym, przez 12 W w tabletach, 20-40 W w ultracienkich laptopach z aktywnym chłodzeniem, aż po 60-100 W w większych konstrukcjach. Architektura jest gotowa na przyszłe zastosowania desktopowe, gdzie pobór mocy może sięgnąć nawet 110-200 W.
A jak z wydajnością pozostałych odmian Snapdragona X2? Bo w rodzinie tej mamy Extreme (18 rdzeni) i dwa rodzaje Elite (18 rdzeni i 12 rdzeni). Wyniki pokazują systematyczny wzrost wydajności:
Geekbench 6.5 Single-Core:
- Extreme: 4074 pkt
- Elite (18 rdzeni): 3829 pkt
- Elite (12 rdzeni): 3829 pkt
Widać, że liczba rdzeni nie wpływa na wydajność pojedynczego wątku.
Geekbench 6.5 Multi-Core:
- Extreme: 20461 pkt
- Elite (18 rdzeni): 16219 pkt
- Elite (12 rdzeni): cóż, nie zdołałem przestestować
Cinebench R24 MT:
- Extreme: 1899 pkt
- Elite (18 rdzeni): 1337 pkt
- Elite (12 rdzeni): 1144 pkt
3DMark Solar Bay (GPU):
- Extreme: 89,4 pkt
- Elite (18 rdzeni): 84.5 pkt
- Elite (12 rdzeni): 68,01 pkt
Wzrost jest systematyczny i przewidywalny - większa liczba rdzeni przekłada się na wyższą wydajność, a GPU pokazuje imponującą skalowalność.
Snapdragon X2 - pewność siebie Qualcomma i nowa szansa dla Windowsa
Po dwóch intensywnych dniach w San Diego spędzonych w siedzibie Qualcomma trudno mieć wątpliwości: firma wie, że stworzyła coś wyjątkowego. Zaproszenie dziennikarzy do laboratorium, pełny dostęp do sprzętu i specjalistów odpowiedzialnych za projekt - to nie jest standard w tej branży. Tak otwarta i transparentna prezentacja świadczy o jednym: Qualcomm jest absolutnie pewny swojego produktu.
I trudno się dziwić. Snapdragon X2 to układ, który da dużo do myślenia starszej i dominującej sprzedażowo konkurencji. Od architektury Oryon Gen 3, przez GPU Adreno X2 z dedykowanym ray tracingiem, po Hexagon NPU osiągający 80 TOPS - każdy element został zaprojektowany tak, by nie tylko dorównać tejże konkurencji, ale ją przeskoczyć. Wydajność jedno- i wielordzeniowa rośnie odpowiednio o 39 proc. i 50 proc., a przy tym układ zachowuje imponującą efektywność energetyczną.
Qualcomm nie ogranicza się do samego hardware’u. Ekosystem oprogramowania – od Snapdragon Control Panel po wsparcie dla najpopularniejszych frameworków AI -pokazuje, że firma myśli o pełnym doświadczeniu użytkownika. Gry działają płynnie, z pełną kompatybilnością antycheatów, a aplikacje kreatywne i narzędzia AI korzystają z mocy NPU bez konieczności sięgania do chmury.
Największe wrażenie robi jednak skalowalność. Snapdragon X2 Elite może pracować w smartfonie przy 5 W, w ultracienkim laptopie przy 20-40 W, a nawet w desktopie przy ponad 100 W. To architektura, która nie zna granic form factorów. Podsumowując: Qualcomm nie tylko dostarczył procesor, który wreszcie pozwala na Windowsie konkurować z Intelem i AMD. Qualcomm pokazał, że ma wizję - i odwagę, by ją realizować. Snapdragon X2 to manifest pewności siebie i technologicznej dojrzałości firmy, która po latach prób wreszcie ma produkt gotowy, by nieco namieszać na cierpiącym na stagnację rynku komputerów osobistych.

To pierwsza z wielu publikacji na Spider's Web o Snapdragonie X2. Qualcomm zapewnił mi w istocie bezprecedensowy wgląd w swoją kuchnię i do wszystkiego co związane z tym układem. Nie sposób wyczerpać temat w jednym tekście, który i tak zdaniem recenzujących go koleżanek i kolegów z redakcji jest już stanowczo zbyt długi. Opowiem o laboratoriach testowych, o tym jak powstaje oprogramowanie na ten układ, o jego ISP i wielu innych. I nie ukrywam - nie mogę się już doczekać przyszłego roku, kiedy pojawią się pierwsze przeznaczone do sprzedaży komputery z tym czipem.