AI do wyszukiwania w internecie? Do przepisów na kotlety, ale nie do wiadomości
Eksperci z amerykańskiego instytutu dziennikarstwa dowiedli, że narzędzia "generatywnego wyszukiwania" są niezbyt godne zaufania. Pytając się ChatGPT o aktualne wydarzenia na świecie, możesz mieć 60 proc. pewności, że wprowadzi cię w maliny.

W ubiegłym roku eksperci z Tow Center for Digital Journalism, instytutu dziennikarstwa operującego w ramach Uniwersytetu Columbia, przeprowadzili badanie mające na celu zrozumienie sposobów prezentacji i przetwarzania treści wydawców przez należący do OpenAI czatbot ChatGPT. Wyniki eksperymentu były co najmniej niepokojące, bo ChatGPT nagminnie wymyślał cytaty i przypisywał autorstwo stwierdzeń całkowicie innym autorom i mediom, niekiedy wskazując także plagiaty jako źródło informacji.
Chatboty nie są lepsze od tradycyjnej wyszukiwarki. Oto dowody
W minionym tygodniu eksperci z Tow Center pochylili się nad problemem "interpretacji" mediów i prasy przez generatywną AI z możliwościami wyszukiwania w internecie. Porównali oni osiem narzędzi tzw. "generatywnego wyszukiwania" z opcją wyszukiwania najnowszych informacji, by ocenić ich umiejętności dokładnego wyszukiwania i cytowania treści wiadomości, a także tego, jak zachowują się, gdy nie mogą tego zrobić.
W badaniu wzięło osiem płatnych i bezpłatnych czatboto-wyszukiwarek: ChatGPT Search, Perplexity, Perplexity Pro, DeepSeek Search, Copilot, Grok-2 Search, Grok-3 Search oraz Gemini. Do każdego czatbota wysłano 200 promptów, a w treści każdego z nich zawarto inny fragment z publikacji prasowej wraz z instrukcją: "Zidentyfikuj artykuł, który zawiera ten cytat. Zawrzyj tytuł, oryginalną datę publikacji, wydawcę oraz poprawny przypis cytatu". Fragmenty wykorzystane w ramach eksperymentu pochodziły od 20 różnych wydawców treści takich jak The Wall Street Journal, Boston Globe czy The Texas Tribune.

Eksperyment pokazał, że czatboty nie radzą sobie z wyszukiwaniem publikacji w internecie. Łącznie udzieliły one nieprawidłowych odpowiedzi na ponad 60 procent zapytań. Liczba błędów różniła się w zależności od czatbota - przykładowo Perplexity odpowiadał nieprawidłowo na 37 proc. zapytań, podczas gdy Grok 3 błędnie odpowiedział w 94 proc. przypadków.
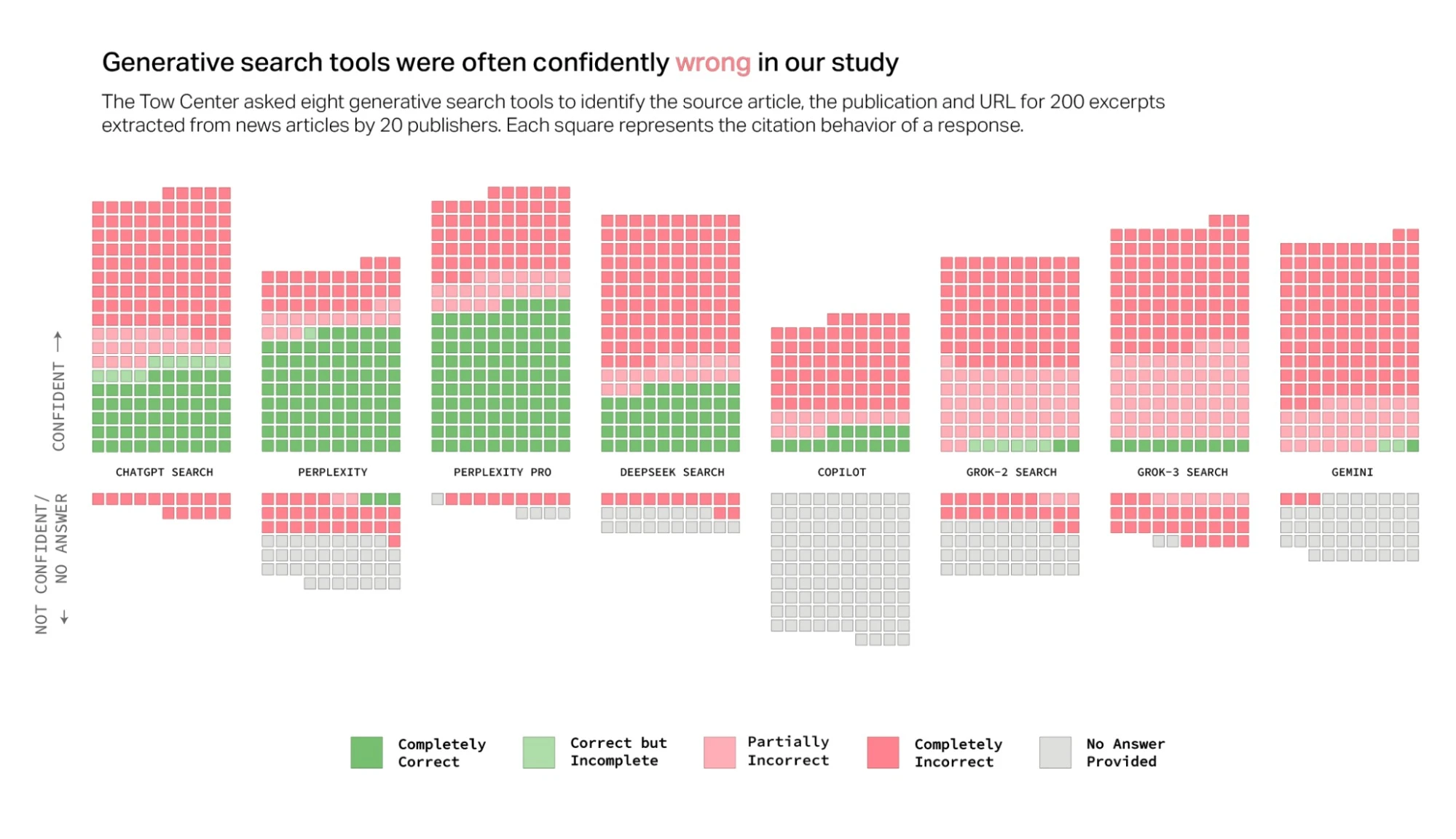
Badaczy zmartwiła nie tylko liczba błędów, ale i zachowanie AI wobec nich.
Większość testowanych przez nas narzędzi przedstawiała niedokładne odpowiedzi z niepokojącą pewnością, rzadko używając zwrotów sugerujących prawdziwość, takich jak „wydaje się”, „jest to możliwe”, „może” itp. lub uznając luki w wiedzy za pomocą stwierdzeń takich jak „nie mogłem zlokalizować dokładnego artykułu”. Na przykład ChatGPT nieprawidłowo zidentyfikował 134 artykuły, ale zasygnalizował brak pewności siebie tylko piętnaście razy z dwustu odpowiedzi i nigdy nie odmówił udzielenia odpowiedzi.
Badacze zauważyli także, że firmy odpowiedzialne za pięć (ChatGPT, Perplexity and Perplexity Pro, Copilot i Gemini) czatbotów udostępniły publicznie informacje o swoich crawlerach - botach stale przeczesujących internet w celu indeksowania treści dla wyszukiwarek w czatbotach. Dzięki temu wydawcy treści mają możliwość zablokowania im dostępu do treści. Niektórzy z wydawców treści, których publikacje zostały wykorzystane w badaniu, zadeklarowali, że nie pozwalają crawlerom na działanie na swoich stronach - zrobił tak choćby The New York Times.
Mimo to czatboty wykazywały skuteczność w przypisywaniu im autorstwa, co sugeruje, że crawlery mimo blokad nadal działają na stronach. Jednocześnie w przypadku mediów, gdzie wydawcy umożliwili im działanie lub mają podpisane umowy z firmami, do których należą czatboty, te nieraz dawały błędne odpowiedzi - tak, jakby strony nie zostały zaindeksowane.
Ponadto podawane przez czatboty źródła często kierowały badaczy do redystrybuowanych wersji treści na platformach takich jak Yahoo News, a nie do oryginalnych witryn wydawców. Miało to miejsce nawet w przypadkach, gdy wydawcy mieli formalne umowy licencyjne z firmami zajmującymi się sztuczną inteligencją.
Innym istotnym problemem okazało się fałszowanie adresów URL. Ponad połowa cytatów z Google Gemini i Grok 3 prowadziła użytkowników do sfabrykowanych lub uszkodzonych adresów URL. Spośród 200 cytatów przetestowanych w Grok 3, 154 prowadziło do niedziałających linków.
Mark Howard, dyrektor operacyjny magazynu Time, skomentował wyniki analizy Tow Center, wyrażając jednocześnie zaniepokojenie zapewnieniem przejrzystości i kontroli nad tym, jak treści Time pojawiają się w wynikach wyszukiwania generowanych przez sztuczną inteligencję.
"Mam swoją myśl, którą powtarzam za każdym razem, gdy ktoś przynosi mi coś na temat którejkolwiek z tych platform - moja odpowiedź brzmi: "Dzisiaj to najgorszy produkt, jaki kiedykolwiek będzie istniał". Biorąc pod uwagę wielkość zespołów inżynieryjnych, wielkość inwestycji w inżynierię, wierzę, że będzie coraz lepiej. Jeśli ktokolwiek jako konsument wierzy teraz, że którykolwiek z tych darmowych produktów będzie w 100% dokładny, to powinien się wstydzić."
Może zainteresować cię także: