Boty uczą się głównie na Uniwersytecie Youtube'a. To bardzo zła wiadomość
Grupa naukowców-wolontariuszy zajmująca się analizą danych, na których trenuje się sztuczną inteligencję, nie ma zbyt dobrych wiadomości. O ile generatywna AI ma się z czego uczyć, to wiedza, którą przyswaja, niezbyt odzwierciedla to, jak rzeczywiście wygląda świat.

Generatywna sztuczna inteligencja taka jak GPT OpenAI - czy sztuczna inteligencja ogólnie - podobnie jak my potrzebuje się uczyć, by być w czymś dobra. O ile w naszym przypadku nauka umiejętności i przyswajanie wiedzy to bardzo skomplikowany i wieloletni proces, którego nie możemy przyspieszyć dając komuś 700 książek i liczyć, że je przeczyta, to w przypadku AI jest trochę inaczej.
Skąd sztuczna inteligencja wie, jak wygląda świat? Z encyklopedii, YouTube i USA
Trening AI (lub jak kto woli, uczenie AI wiedzy o tym co ma robić) przeprowadzany jest z użyciem bardzo dużej ilości różnego rodzaju danych wytworzonych przez ludzi. Dzięki powtarzalności pewnych informacji i wyróżnieniu przez sztuczną inteligencję schematów ich występowania AI jest w stanie nauczyć się, że gdy mówi się o szczekającym zwierzęciu, zwykle jest to pies, że niebo jest niebieskie, albo że na podstawie pewnych cech wizualnych można wskazać, które grzyby są trujące.
Jednak dane te nie pochodzą znikąd i AI, tak jak my, uczy się na podstawie informacji z książek, prasy czy szeroko pojętych mediów. Ale skąd konkretnie? Na to nietypowe pytanie postanowili odpowiedzieć naukowcy i inżynierowie wchodzący w skład Data Provenance Initiative, grupy ekspertów-wolontariuszy, którzy przeprowadzają audyty popularnych zbiorów danych tekstowych, graficznych, mowy i wideo, śledząc ich pochodzenie i tworzenie, katalogując źródła danych, licencje, twórców i inne metadane, które później są przetwarzane przez naukowców.
Data Provenance Initiative podzieliło się z MIT Technology Review wnioskami, jakie grupa badaczy uzyskała po analizie prawie 4000 publicznych zestawów danych treningowych dla AI obejmujących ponad 600 języków, 67 krajów i trzy dekady. Dane w zestawie pochodzą z 800 unikalnych źródeł i prawie 700 organizacji. Jak pokazują wyniki analizy, źródła danych dla AI z każdym rokiem stają się coraz bardziej podporządkowane dużym koncernom technologicznym.
W pierwszej dekadzie XXI wieku badacze uczenia maszynowego i sztucznej inteligencji najczęściej do treningu sieci neuronowych używali różnego rodzaju danych - encyklopedii, danych z internetu, transkrypcji obrad parlamentów, transkrypcji telekonferencji poświęconych omówieniu wyników finansowych (tzw. earning calls) czy na transkrypcji prognoz pogody. A to ze względu na fakt, że wcześniej systemy sztucznej inteligencji szkolono z myślą o jednym, konkretnym zadaniu.
Przełomem dla uczenia maszynowego i sztucznej inteligencji był rok 2017, kiedy opracowano architekturę Transformer - tę z której obecnie korzysta rodzina modeli GPT OpenAI, Gemini Google oraz inne popularne dziś duże modele językowe sztucznej inteligencji. Równocześnie odkryto, że im większe i bardziej różnorodne zestawy danych, tym lepsze stają się modele AI - stąd na przełomie 2017 i 2018 roku można zauważyć zarówno dodanie licznych nowych źródeł danych, jak i zwiększenie się samych zestawów danych.
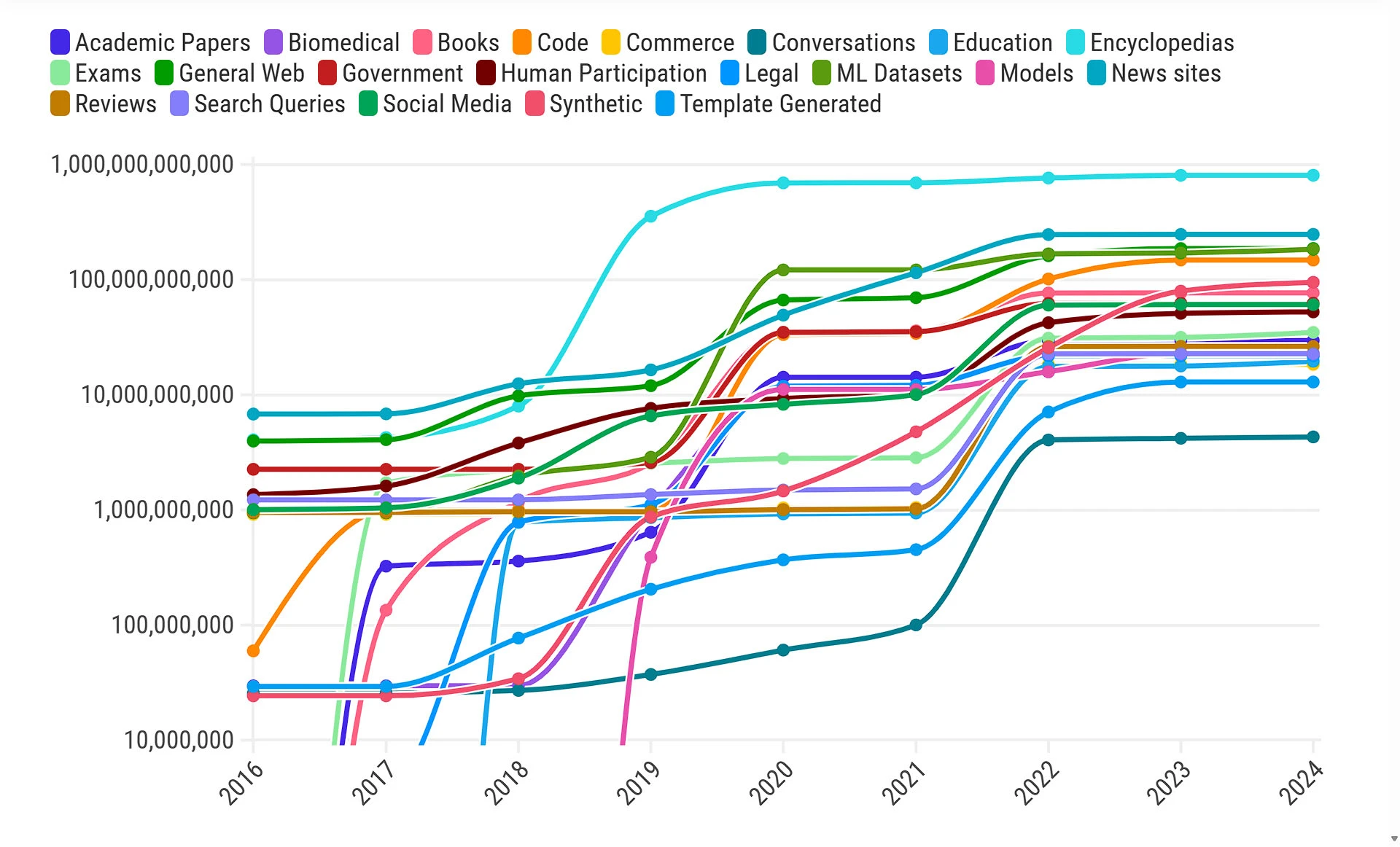
W przypadku modeli tekstowych najpopularniejszymi źródłami informacji są encyklopedie, publikacje prasowe, specjalnie przygotowane zestawy danych (takie jak np. Enron Corpus - zbiór danych 600 tys. emaili pracowników amerykańskiej firmy Enron), dane ogólnie z internetu oraz kod programistyczny
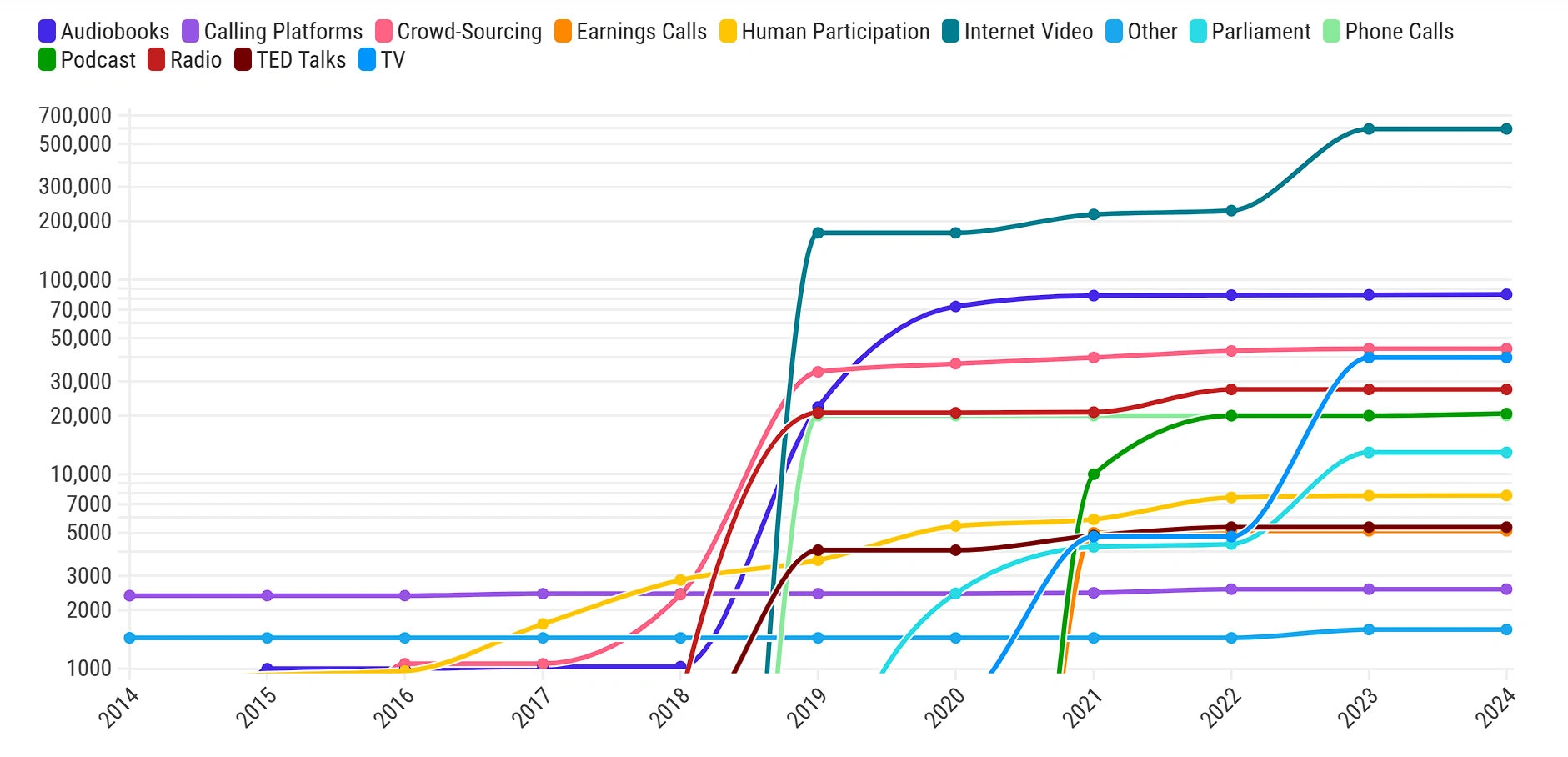
Podobne zjawisko zaobserwowano także w zestawach danych zawierających język mówiony, gdzie nagły skok odnotowano w latach bezpośrednio następujących po 2017 roku. Tu najczęściej dane pochodzą z filmów w internecie, audiobooków, dane zebrane w ramach crowdsourcingu, telewizji i radia.
Jednocześnie Data Provenance Initiative zauważyło, że 70 proc. danych wideo dla modeli AI pochodzi z jednego źródła - YouTube.
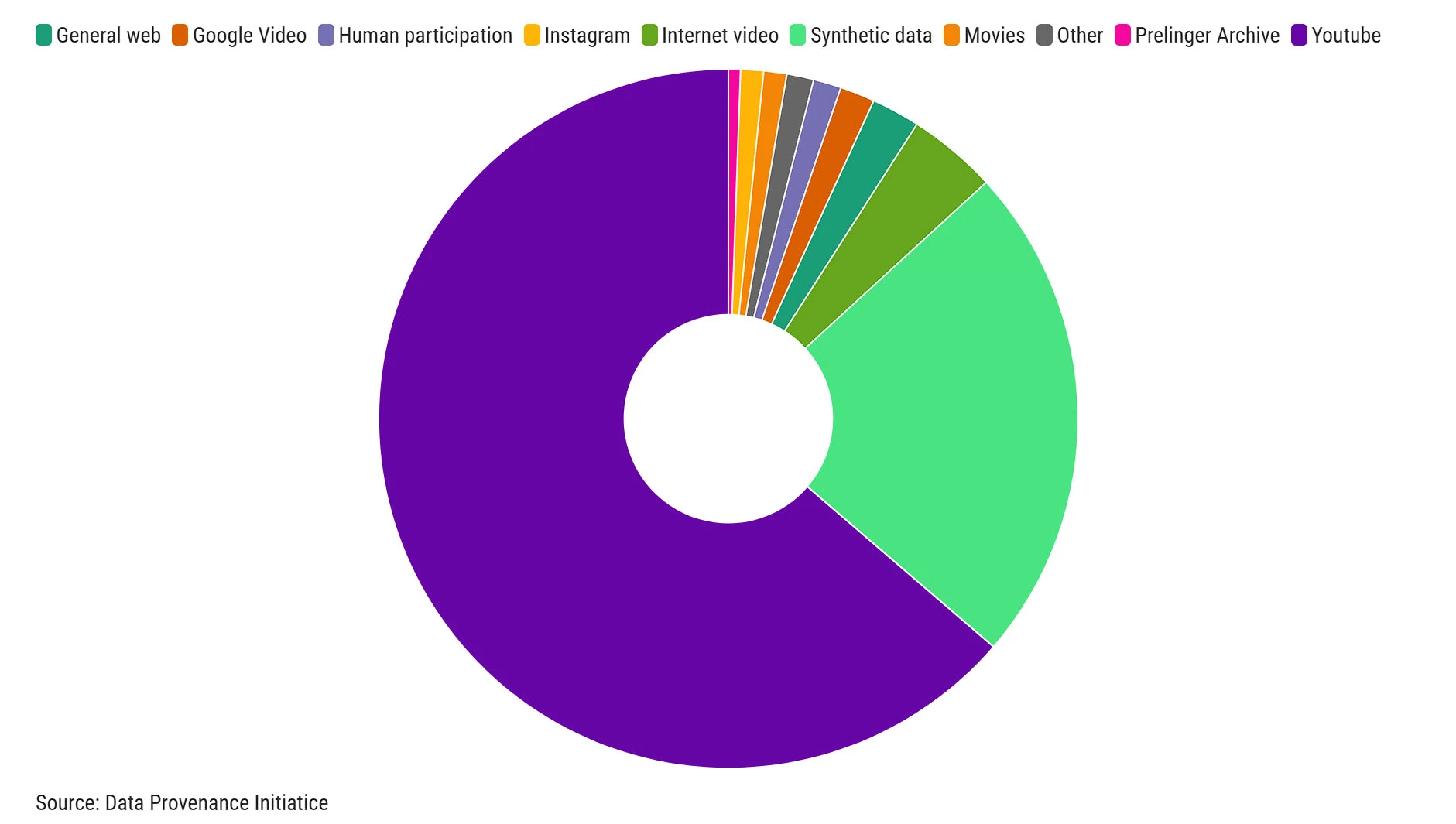
Tak duża zależność od jednego źródła, które w dodatku jest w posiadaniu koncernu rozwijającego własną sztuczną inteligencję, budzi obawy naukowców o zarówno manipulację danymi, jak i o możliwe odcięcie dostępu do danych.
Ważne jest, aby myśleć o danych nie jak o naturalnie występującym zasobie, ale jak o czymś, co powstaje w wyniku określonych procesów. Jeśli zbiory danych, na których opiera się większość sztucznej inteligencji, z którą wchodzimy w interakcje, odzwierciedlają intencje i projekty dużych, motywowanych zyskiem korporacji - to przekształcają infrastrukturę naszego świata w sposób odzwierciedlający interesy tych wielkich korporacji
Naukowcy podjęli się też analizy licencji danych zawartych w zestawach treningowych. W zdecydowanej większości dane, na których trenuje się AI to mieszanka danych chronionych prawami autorskimi i danych co do licencji naukowcy nie są pewni. W przypadku zestawów danych tekstowych jedynie 18 proc. zawartych w nich danych było tylko do użytku niekomercyjnego lub zostało opublikowanych na licencjach pozwalających na legalny użytek.
Jeszcze bardziej niepokojącym zjawiskiem jest silna koncentracja zestawów danych w Europie i Stanach Zjednoczonych, z których pochodzi ich aż 90 proc., a z samych Stanów Zjednoczonych ponad trzy czwarte wszystkich analizowanych zestawów. Ponadto ponad 90 proc. z nich zawiera dane w większości lub wyłącznie w języku angielskim, co w połączeniu z ich pochodzeniem budzi obawy o jednowymiarowość i amerykańskocentryczność trenowanych na nich systemów sztucznej inteligencji.
Te zestawy danych odzwierciedlają jedną część naszego świata i naszej kultury, ale całkowicie pomijają inne. Używamy tych modeli na całym świecie i istnieje ogromna rozbieżność między światem, który widzimy, a tym, co jest niewidoczne dla tych modeli.
Może zainteresować cię także: