Reddit i Perplexity biorą się za łby. To wojna o przyszłość internetu
Czy wyszukiwarki AI kradną dane, czy też robią to samo, co białkowy użytkownik - tylko szybciej? Do kogo właściwie należą publicznie dostępne dane? O tym zdecyduje sąd, a jego decyzja może mieć duży wpływ na większość z nas.

Czasami pojedyncza sprawa sądowa może zdefiniować relacje między całymi sektorami technologicznymi na lata - i właśnie taki potencjał ma pozew, który złożył Reddit w nowojorskim sądzie federalnym. Platforma społecznościowa oskarża startup Perplexity AI oraz trzy firmy zajmujące się scrapingiem danych o systematyczne i nielegalne wykradanie treści z platformy w celu szkolenia modeli sztucznej inteligencji. Już powierzchownie patrząc widać istotę problemu - to starcie wizji tego, jak powinien wyglądać Internet w erze AI, o to kto ma prawo do danych generowanych przez użytkowników i czy istnieje coś takiego jak darmowy lunch w świecie sztucznej inteligencji.
Główny radca prawny platformy Reddit, Ben Lee, nazwał całe zjawisko przemysłem prania danych na skalę przemysłową, w którym firmy AI toczą wyścig zbrojeń o pozyskanie wysokiej jakości treści generowane przez ludzi. To mocne słowa, ale stojące za nimi liczby są jeszcze bardziej wymowne - Reddit ma licencjonować swoje dane Google i OpenAI za łącznie około 130 mln dol. rocznie. Perplexity, według zarzutów, postanowiło pominąć tę drobną formalność zwaną płaceniem.
Czytaj też:
Anatomia kradzieży danych - jak to miało działać
Pozew Reddita ujawnia fascynujący, choć kontrowersyjny ekosystem firm, które wyspecjalizowały się w jednym: obchodzeniu zabezpieczeń i wyciąganiu danych z miejsc, gdzie nie powinny mieć dostępu. Obok Perplexity w roli głównej pozwani zostali: litewska firma Oxylabs, teksańska SerpApi oraz rosyjski AWMProxy - ten ostatni określony przez Reddit jako były rosyjski botnet.
Schemat działania, jaki opisuje pozew, jest jednocześnie prosty i wyrafinowany. Firmy scrapingowe nie próbowały bezpośrednio atakować serwerów Reddit - to byłoby zbyt oczywiste i łatwe do zablokowania. Zamiast tego wykorzystywały lukę w ekosystemie: wyniki wyszukiwania Google. SerpApi, Oxylabs i AWMProxy specjalizują się w ekstrakcji danych z wyników wyszukiwania Google (SERP - Search Engine Results Pages), oferując te informacje jako usługę dla klientów AI.
Reddit twierdzi, że te firmy maskowały swoje tożsamości, ukrywały lokalizacje i przebierały swoje scrapery za zwykłych użytkowników, aby obejść zabezpieczenia techniczne. Perplexity miałoby być klientem tych firm - kupując skradzione dane zamiast negocjować legalne umowy licencyjne z Redditem.
Pułapka na domniemanego złodzieja
Reddit stworzył specjalny post testowy, który był widoczny wyłącznie dla robota indeksującego Google - nie pojawiał się nigdzie na samym Reddicie. Jeśli ten unikalny, ukryty content pojawi się w odpowiedziach generowanych przez AI Perplexity to będzie to dowód na to, że firma korzysta z danych scrapowanych z Google’a, a nie z legalnego dostępu do Reddita.
Post pojawił się w wynikach Perplexity w ciągu kilku godzin. Reddit argumentuje: Jedynym sposobem, w jaki Perplexity mogło uzyskać dostęp do tej treści i użyć jej w swojej 'odpowiedzi', było scrapowanie wyników wyszukiwania Google.
Reddit twierdzi, że wysłał do Perplexity pismo wzywające do zaprzestania działań (cease-and-desist) w maju ubiegłego roku, żądając natychmiastowego zaprzestania scrapowania danych Reddita bez licencji. Perplexity najwyraźniej potraktowało to wezwanie jako sugestię, którą należy zignorować. Ba, według pozwu, po otrzymaniu pisma cytowania treści z Reddita w odpowiedziach Perplexity zwiększyły się czterdziestokrotnie.
Reddit interpretuje to jako świadome lekceważenie praw własności intelektualnej i dowód na to, że Perplexity nie ma zamiaru respektować żadnych zasad, jeśli stoją one na przeszkodzie w dostępie do cennych danych treningowych.
Perplexity odpiera zarzuty: to nie kradzież, to agregacja
Oczywiście Perplexity nie zamierza przyjąć tych oskarżeń z pokorą. W oficjalnej odpowiedzi opublikowanej na... no właśnie, na samym Reddicie (ironia sytuacji jest nieoceniona) startup oskarżył Reddit o wymuszenie i o atak na otwarty Internet.
Nasze podejście pozostaje zasadnicze i odpowiedzialne, gdy dostarczamy bazujące na faktach odpowiedzi przy użyciu precyzyjnej AI i nie będziemy tolerować zagrożeń dla otwartości i interesu publicznego - brzmi oświadczenie Perplexity. Firma podkreśla, że nie szkoli swoich modeli AI na treściach Reddita - twierdzi, że jedynie cytuje streszczenia publicznych dyskusji z platformy, co ich zdaniem czyni umowy licencyjne trudnymi do uzasadnienia.
Perplexity poszło jeszcze dalej sugerując, że pozew Reddita to nie tyle ochrona praw użytkowników, ile pokaz siły w negocjacjach Reddita dotyczących danych treningowych z Google’em i OpenAI. Innymi słowy: Reddit nie walczy o zasady, tylko próbuje wymusić lepsze warunki finansowe w swoich istniejących dealach, używając Perplexity jako kozła ofiarnego. Argumentacja startupu jest prosta: jeśli dane są publicznie dostępne w Internecie, to każdy powinien mieć prawo do ich agregowania i streszczania.
SerpApi też się odcina: stanowczo się nie zgadzamy
SerpApi, jedna z pozwanych firm, również odmówiła przyznania się do winy. Firma oświadczyła, że stanowczo się nie zgadza z zarzutami Reddita i będzie się bronić w sądzie. To istotne, bo SerpApi to nie bezimienne narzędzie z dark webu - to firma oferująca legalną usługę API do wyników wyszukiwania Google, używaną przez tysiące programistów i firm na całym świecie.
SerpApi twierdzi, że jej usługa jest legalna i zgodna z precedensami sądowymi, takimi jak sprawa hiQ Labs przeciwko LinkedIn, w której sąd orzekł, że scrapowanie publicznie dostępnych danych nie stanowi nieautoryzowanego dostępu w rozumieniu Computer Fraud and Abuse Act (CFAA). Problem w tym, że ta sprawa dotyczyła danych już widocznych publicznie na LinkedInie.
Oxylabs i AWMProxy jak dotąd milczą - co w przypadku tej drugiej firmy, określanej jako były rosyjski botnet, może nie być wielkim zaskoczeniem.
Reddit to forteca danych
Żeby zrozumieć dlaczego Reddit tak zaciekle walczy o swoje dane to trzeba spojrzeć na szerszy kontekst. Reddit to jedna z największych i najbardziej dynamicznych baz ludzkiej konwersacji w Internecie - ponad miliard postów i 16 mld komentarzy organizowanych w tysiące tematycznych subredditów. To kopalnia złota dla firm AI, które potrzebują autentycznych, nieszablonowych ludzkich dialogów do trenowania swoich modeli językowych.
Reddit zdał sobie sprawę z wartości tych danych i w 2023 r. CEO Steve Huffman podjął decyzję, która wywróciła do góry nogami dotychczasowy model: platforma drastycznie podniosła ceny dostępu do swojego API, skutecznie blokując darmowy dostęp dla firm AI. Nie zamierzamy oddawać naszych danych niektórym z największych firm na świecie za darmo - powiedział Huffman.
To zaowocowało lukratywnymi umowami licencyjnymi: około 60 mln dol. rocznie od Google’a i szacunkowo 70 mln od OpenAI. Te umowy stanowią około 10 proc. przychodów Reddita i są kluczowe dla strategii monetyzacji platformy po wejściu na giełdę. Umowy te obejmują nie tylko dostęp do danych, ale też mechanizmy ochrony prywatności użytkowników - jak Compliance API, które powiadamia licencjobiorców, gdy użytkownicy usuwają swoje posty, zmuszając firmy AI do zaprzestania wykorzystywania tych treści.
Reddit ma już doświadczenie w walce z nielegalnym scrapingiem - w czerwcu pozwał Anthropic (twórcę Claude AI) z podobnych powodów. Ten pozew jest więc częścią większej kampanii mającej na celu ustanowienie precedensu: dane użytkowników nie są darmowym zasobem dla każdego, kto ma umiejętności programistyczne.
Perplexity i ich kontrowersyjna historia scrapingu
Warto zaznaczyć, że to nie pierwszy raz, gdy Perplexity jest oskarżane o agresywne praktyki zbierania danych. W czerwcu ubiegłego roku Forbes publicznie oskarżył startup o plagiat artykułu, który Perplexity rzekomo prawie całkowicie skopiował w swojej funkcji Perplexity Pages, nie podając nawet odpowiednio źródła. Wired z kolei przeprowadził śledztwo wykazujące, że Perplexity ignoruje protokół robots.txt - standardowy mechanizm, który pozwala właścicielom stron internetowych wskazać, że nie chcą, aby ich treści były scrapowane przez boty.
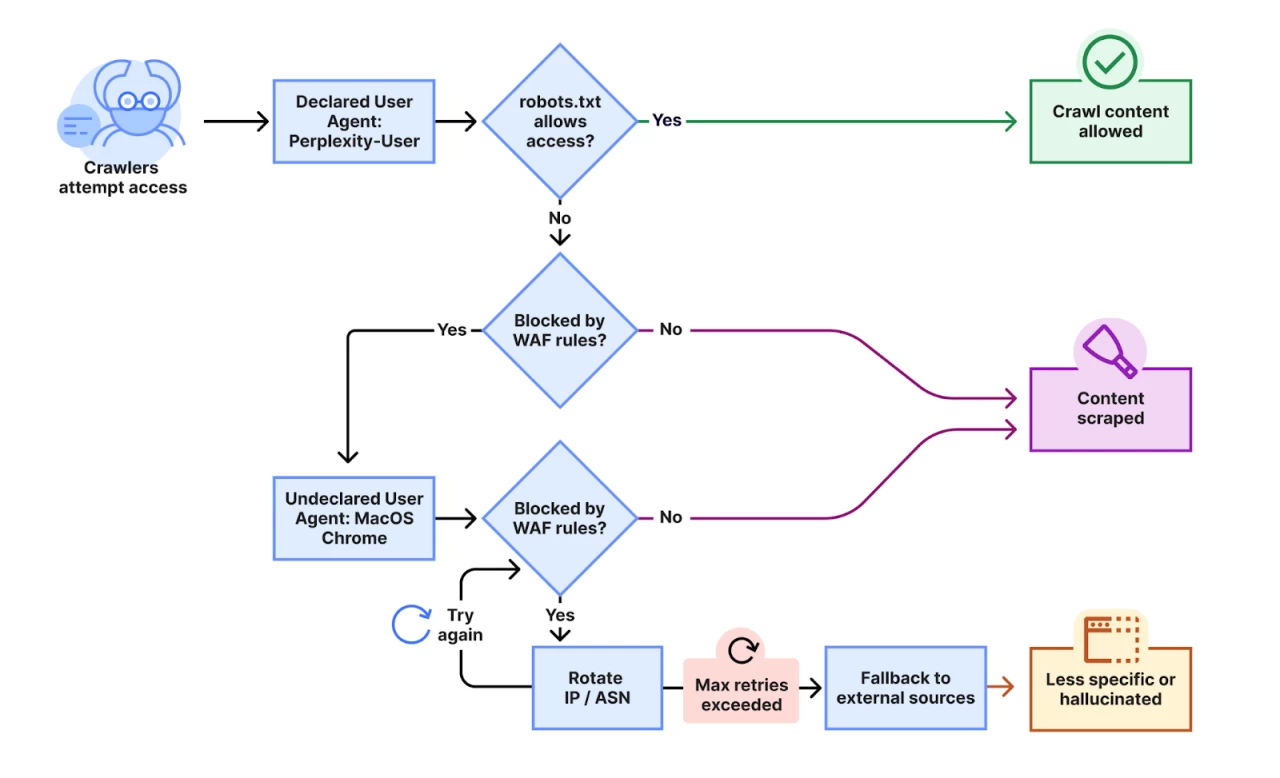
Wired i niezależny developer Robb Knight odkryli, że Perplexity używa nieujawnionych adresów IP i fałszywych identyfikatorów user-agent, aby ominąć te zabezpieczenia - podczas gdy publicznie firma twierdzi, że przestrzega protokołu.
W październiku ubiegłego roku Dow Jones i New York Post złożyli pozew przeciwko Perplexity za naruszenie praw autorskich. Inwestorzy jednak nie wydają się tym zaniepokojeni - Perplexity wspierane przez Jeffa Bezosa i Nvidię, osiągnęło wycenę około 9 mld dol. w listopadzie 2024, a w marcu 2025 podobno prowadziło rozmowy o kolejnej rundzie finansowania, która podniosłaby wycenę do 18 mld dol.
To ma bezpośredni wpływ na nasz Internet
Ben Lee z Reddita użył określenia data laundering - pranie danych - i to trafna metafora. Opisuje on ekosystem, w którym firmy scrapingowe pełnią rolę pośredników, wyciągając dane z miejsc chronionych zabezpieczeniami i piorąc je przez warstwę technologicznej abstrakcji, zanim sprzedadzą je jako usługę firmom AI, które mogą udawać, że nie wiedzą, skąd te dane pochodzą.
To stawia fundamentalne pytanie o przyszłość Internetu: czy dane publicznie dostępne w sieci są automatycznie wolne do wykorzystania przez firmy komercyjne? Czy fakt, że możesz coś zobaczyć oznacza, że możesz to automatycznie kopiować na masową skalę i sprzedawać?
Precedensy prawne nie są tu pomocne. Sprawa hiQ vs. LinkedIn sugerowała, że scrapowanie publicznych danych może być legalne. Ale inne orzeczenia - szczególnie te dotyczące obchodzenia zabezpieczeń technicznych czy łamania warunków korzystania - wskazują na odpowiedzialność prawną. Sądy często interpretowały próby obejścia zabezpieczeń jako dowód świadomego naruszenia prawa.
Reddit argumentuje, że pozwani obchodzili zabezpieczenia techniczne zaprojektowane w celu ochrony przed taką działalnością, wszystko na skalę przemysłową. Jeśli sąd się z tym zgodzi to może to stworzyć precedens, który zmusi firmy AI do zawierania umów licencyjnych zamiast polegania na scrapingu.
Reddit domaga się nieokreślonych odszkodowań finansowych i nakazu sądowego zabraniającego Perplexity wykorzystywania jego danych. Ale prawdziwa stawka jest znacznie większa niż konkretne kwoty.
Jeśli Reddit wygra to może to zainicjować falę podobnych pozwów od innych platform społecznościowych i wydawców medialnych, które czują się wykorzystywane przez firmy AI. Może to zmusić cały sektor AI do przebudowy swoich praktyk pozyskiwania danych - od scrapingu wszystkiego, co się da do negocjowania formalnych umów licencyjnych.
Z drugiej strony - jeśli Perplexity wygra na podstawie argumentu fair use to może to otworzyć drzwi dla mniejszych startupów AI, które nie mają budżetów na licencjonowanie danych od każdej platformy. Może to demokratyzować rozwój AI - ale kosztem twórców treści i platform, które te treści hostują.
To także sprawa o kontrolę nad narracją w erze AI. Perplexity i podobne answer engines nie tylko wykorzystują dane - one je przetwarzają, streszczają i prezentują użytkownikom jako ostateczne odpowiedzi, często bez konieczności klikania na oryginalne źródło. To zmienia ekonomię Internetu: jeśli użytkownicy dostają odpowiedzi bezpośrednio od AI zamiast odwiedzać źródłowe strony to te strony tracą ruch, reklamy i przychody.
Reddit to zauważył: platforma twierdzi, że ruch z Google’a ma ograniczoną wartość, bo użytkownicy szukający szybkiej odpowiedzi na pytanie często nie konwertują się na aktywnych Redditorów. Dlatego Reddit prowadzi rozmowy o głębszej integracji z produktami AI Google’a, próbując zapewnić, że użytkownicy będą kierowani głębiej do ekosystemu Reddita zamiast dostawać szybkie streszczenie i odchodzić.
Czy będziemy żyli w świecie, gdzie każda interakcja online jest potencjalnym towarem do sprzedaży temu, kto da najwyższą ofertę w licytacji? Czy powstanie system licencjonowania danych, który de facto uprzywilejuje wielkie korporacje mogące sobie pozwolić na płacenie za dostęp? Czy mniejsze startupy AI zostaną zamknięte poza ekosystemem danych wysokiej jakości? A może sądy uznają, że publicznie dostępne dane powinny pozostać wolne dla każdego, kto chce je wykorzystać do budowania nowych technologii?
To pytania, na które odpowiedzi poznamy w ciągu najbliższych miesięcy, gdy sprawa Reddit vs. Perplexity będzie przetwarzana przez system sądowy. I choć brzmi to mniej ekscytująco niż bezgraniczny rozwój AI to być może właśnie taka jest cena dojrzewania technologii - moment, gdy trzeba przestać zachowywać się jak na dzikim zachodzie i zacząć grać według reguł.
*Zdjęcie otwierające: miss.cabul / Shutterstock