Internet zrewolucjonizował świat. Teraz czas zrewolucjonizować Internet, czyli Sieć bez serwerów
Działanie Internetu jest proste. W dużym skrócie – wszystkie urządzenia, np. smartfony i komputery, łączą się z serwerami, które przechowują dane. Tak było od zawsze i w tej kwestii nic się nie zmieniło. Jednak naukowcy z Cambridge wymyślili nowy sposób, który pozwalałby na działanie Sieci bez serwerów.

W tym momencie, jeśli kilka osób jednocześnie chce obejrzeć jakiś film online, to wszystkie one łączą się z serwerem, na którym znajduje się dany materiał. Problemem może być sytuacja, w której dany serwer znajduje się dość daleko od naszego komputera lub kiedy jest on mocno przeciążony i przez to nie wszyscy mogą obejrzeć to, co by akurat chcieli. Niestety, tak to dzisiaj działa i niewiele jesteśmy w stanie z tym zrobić. Ale naukowcy z Uniwersytetu Cambridge wpadli na nieco odmienny pomysł.
Idea jest bardzo prosta. Skoro na co dzień korzystamy z komputerów, smartfonów, tabletów i wszelkiej maści urządzeń, które przechowują dane, to czemu by ich nie wykorzystać, aby odciążyć serwery albo całkowicie z nich zrezygnować. Projekt o nazwie Pursuit zakłada, że Internet mógłby działać na zasadach podobnych do sieci BitTorrent. Oznacza to, że jeśli chcielibyście pobrać z Sieci coś, co już na swoim dysku ma np. wasz sąsiad, to plik ściągalibyście właśnie z jego komputera, a nie serwera mieszczącego się w innym państwa, a może nawet na innym kontynencie.
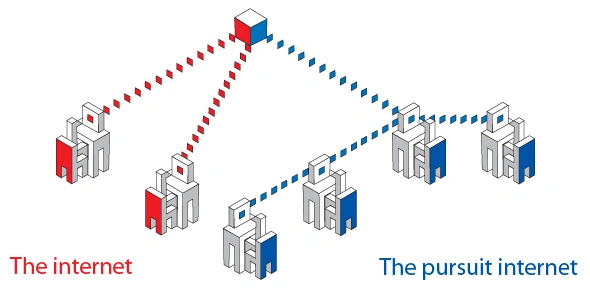
Wyobraźmy sobie taką sytuację. Wchodzę na jakiś serwis z filmami na życzenie i włączam sobie powiedzmy Hobbita. Obejrzałem już 10 minut filmu. W tym czasie inna osoba z mojego miasta korzysta z tej samej strony i również chce obejrzeć przygody Bilbo Bagginsa. Czemu ma łączyć się z serwerem skoro pierwsze 10 minut może mieć ode mnie, kolejne 10 minut od kogoś z Torunia (mieszkam w Bydgoszczy, więc do Torunia mam blisko) i tak dalej. Pozwoliłoby to nie tylko odciążyć serwery, ale też przyspieszyć pracę całego Internetu. Tak przynajmniej zakładają twórcy tego mechanizmu.
Dość ciekawie prezentuje się kwestia tego, jak projekt Pursuit miałby odnajdywać dane treści w całym Internecie. Nie wykorzystywałby do tego adresów www, jak dzieje się to teraz, a coś w rodzaju „odcisków palców”. Zespół odpowiedzialny za ten system zaprezentował nawet aplikację, która wyszukiwałaby pliki w taki sposób, czym udowodnili, że jest to w pełni możliwe.
Poza tym działająca w ten sposób Sieć mogłaby rozwiązać problem zcentralizowania światowego Internetu. Skoro wszystko jest teraz przechowywane na serwerach, to dla służb specjalnych nie jest problemem dostanie się do konkretnych danych czy też śledzenie naszych poczynań w Sieci. Jeśli wszystko byłoby rozsiane po różnych urządzeniach na całym świecie, to z pewnością byłoby to o wiele trudniejsze zadanie.
Jest jednak pewien problem, a w sumie to dwa lub nawet trzy problemy. Po pierwsze, pojemność urządzeń, przede wszystkim przenośnych. Jeśli mam w smartfonie 8 czy 16 GB pamięci masowej, to raczej nie uśmiecha mi się sytuacja, w której część tej przestrzeni jest zajmowana przez nieużywane już przeze mnie pliki, tylko po to, aby inni mogli mieć do nich dostęp. Po drugie, korzystanie z sieci komórkowych jest dość kosztowne. Mam swój pakiet danych i raczej nie chciałby, aby został on zmarnowany przez inne osoby. W końcu wysyłanie plików też go używa. Po trzecie – baterie. Te w smartfonach, a także w tabletach i innych urządzeniach przenośnych już teraz nie wytrzymują zbyt długo bez podłączenia do gniazda zasilania. Tego typu Sieć tylko powiększyłaby ten problem.
Sam pomysł jest zdecydowanie godny uwagi, ale jest przy nim jeszcze zbyt wiele znaków zapytania, aby uznać go za sensowny. Poza tym wprowadzenie go wymagałoby kolosalnych zmian we wszystkich urządzeniach, na co raczej nie ma zbyt wielu szans. Poza tym, gdyby nagle nie był dostępny nikt, kto miałby w swojej pamięci jakąś stronę internetową, to jakbyśmy się na nią dostali? A co z nowymi wpisami, np na Spider's Web, których nikt jeszcze nie widział?
Zdjęcie Best Internet Concept of global business from concepts series pochodzi z serwisu Shutterstock