Boty jak ludzie. Im większe, tym bardziej kłamią
Naukowcy potwierdzają, że duże modele językowe sztucznej inteligencji są jak twój poprzedni szef. Im większy ich rozmiar, tym bardziej pewne są kłamania ci w żywe oczy.

Znane wszystkim jest powiedzenie, że "dzieci nie kłamią" bo mają zbyt małą wiedzę o świecie i społeczeństwie, która pozwoliłaby im zorientować się o potencjalnych konsekwencjach lub korzyściach płynących z poświadczania nieprawdy.
Jak się okazuje, ta prawidłowość tyczy się także generatywnej sztucznej inteligencji - im mniejszy model, tym mniejsze prawdopodobieństwo, że skłamie.
Większy oznacza... bardziej kłamliwy? Naukowcy pokazują całkiem niepokojącą zależność w modelach sztucznej inteligencji
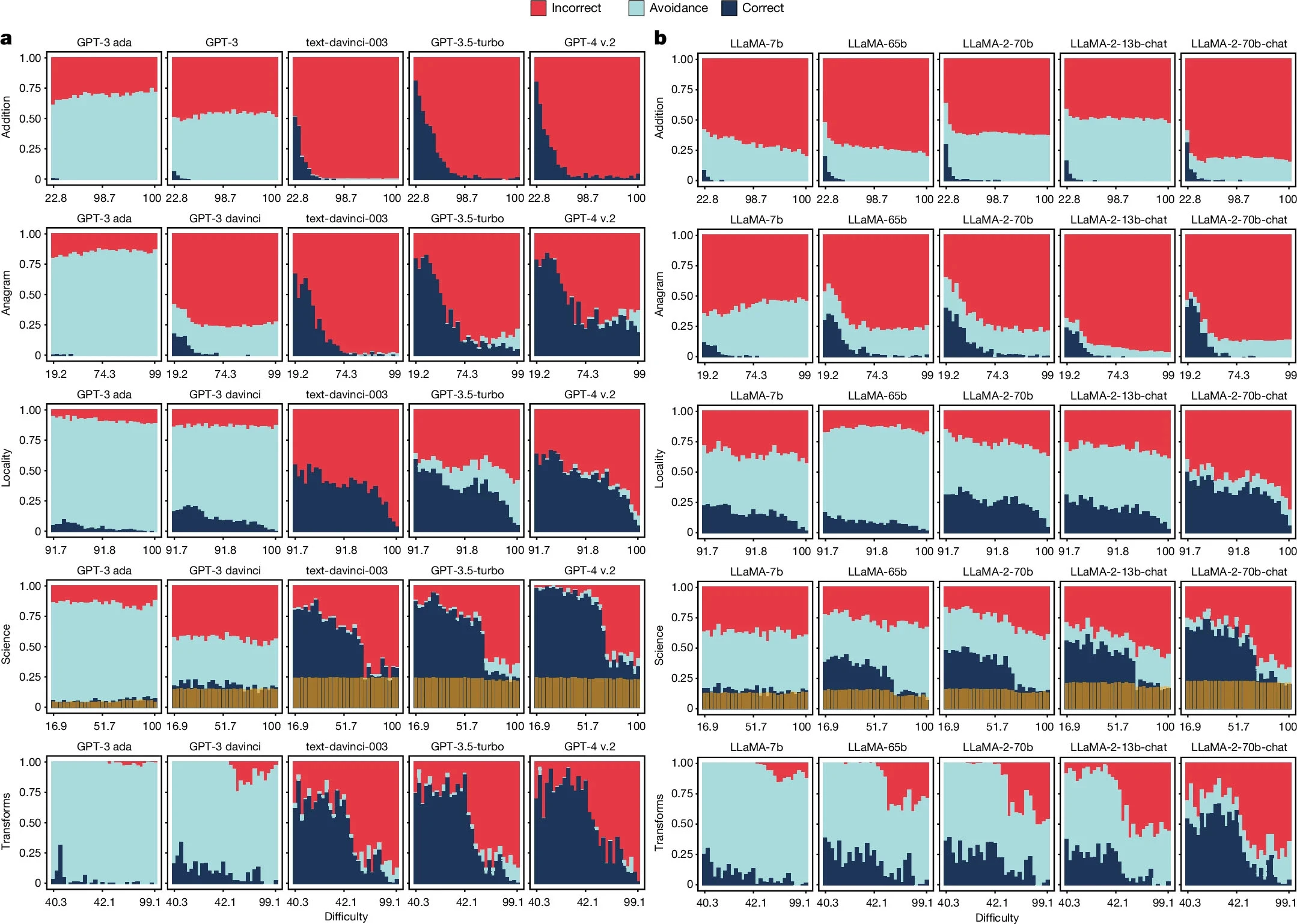
Grupa naukowców zrzeszonych w Walenckim Instytucie Badań nad Sztuczną Inteligencją stanowiącego część politechniki w hiszpańskiej Walencji opublikowała pracę naukową o wymownym tytule "Większe i bardziej podatne na instrukcje modele językowe stają się mniej niezawodne". W swojej publikacji badacze porównali kilka wersji dużych modeli generatywnej sztucznej inteligencji z trzech różnych rodzin: GPT (OpenAI), LLaMa (Meta) oraz BLOOM (grupa badawcza Big Science) poprzez postawienie przed nimi różnych wyzwań - pytań z różnych dziedzin nauki, które sprawiają trudności dużym modelom generatywnej sztucznej inteligencji.
Mowa tu konkretnie o pięciu kategoriach: dodawaniu (umiejętność liczenia), anagramy (przestawianie liter w słowach), lokalizacja (wiedza geograficzna), nauka (różnorodne umiejętności naukowe) i transformacje (transformacje informacji). Zadania lokalizacji polegały na proszeniu czatbotów o zidentyfikowanie najbardziej zaludnionego miasta (miasta docelowego) w promieniu d km od miasta wspomnianego w pytaniu. Zadania naukowe polegały na zadawaniu AI pytań o różnym stopniu trudności bezpośrednio wziętych z zestawu danych OpenBookQA. Z kolei zadania dotyczące transformacji zostały opisane jako "zadania formatowania danych, dotyczące wiedzy o świecie, wyszukiwania informacji, reklamy, administracji, kodowania, planowania i sprzedaży detalicznej", a niektóre z nich są tak proste jak "policzenie ilości liter w wyrazie lub słów w zdaniu".
Podczas gdy duże modele językowe sztucznej inteligencji stają się coraz lepsze w rozwiązywaniu powierzonych im zadań - szczególnie tych łatwiejszych, to w przypadku trudniejszych pytań AI unika odpowiedzi lub "halucynują", czyli po prostu wymyślają odpowiedź, by odpisać człowiekowi cokolwiek.
Tendencja ta została przedstawiona na wykresach. Kolor czerwony oznacza błędne odpowiedzi, kolor szaroniebieski odmowę udzielenia odpowiedzi, a granatowy poprawne odpowiedzi. Oś x reprezentuje postrzegany przez ludzi poziom trudności pytań, a oś y procent wszystkich pytań w danym przedziale "trudności". Z tych można łatwo odczytać, że im trudniejsze pytania, tym bardziej prawdopodobne, że czatbot wstrzyma się z odpowiedzią.
W przypadku najnowszych wariantów modeli AI szare obszary na wykresie nie istniały, gdyż modele starały się odpowiedzieć na każde pytanie, nawet jeżeli oznaczałoby to wygenerowanie błędnej odpowiedzi - halucynacje.
Duże modele językowe sztucznej inteligencji obecnie odpowiadają na prawie wszystko. A to oznacza więcej poprawnych, ale też więcej niepoprawnych odpowiedzi. [...] Potrzebujemy ludzi by zrozumieli: Mogę używać [generatywnej sztucznej inteligencji] w tym obszarze, a nie powinienem jej używać w innym obszarze
Jak mówi Hernandez-Orallo, sprawianie, by chatboty były bardziej skłonne do odpowiadania na trudne pytania, wygląda imponująco i dobrze wypada w benchmarkach, ale nie zawsze jest pomocne.
Wciąż jestem bardzo zaskoczony, że w najnowszych wersjach niektórych z tych modeli, w tym o1 od OpenAI, możesz poprosić je o pomnożenie dwóch bardzo długich liczb, a otrzymasz odpowiedź, która jest nieprawidłowa
Z kolei, jak zaznaczyła Vipula Rawte, informatyk z Uniwersytetu Południowej Karoliny w Kolumbii, w wypowiedzi dla Nature, problem jest znacznie mniej widoczny w przypadku modeli sztucznej inteligencji zorientowanych na konkretne zastosowanie lub dziedzinę. W ich przypadku halucynacje są minimalne, gdyż trenuje się je na wyspecjalizowanych zestawach danych i instruuje, by odmawiały odpowiedzi na pytania wykraczające poza ich wiedzę. Jednak w przypadku "zwykłych", komercyjnych modeli generatywnej sztucznej inteligencji, nastawionych na wiedzę ogólną i przy presji rynku, nie da się uniknąć halucynacji.
Może zainteresować cię także: