OpenAI chce kontrolować, jak używany jest ChatGPT. Jak na razie słabo to wygląda
ChatGPT stał się szkolnym hitem i szkolnym problemem. OpenAI chce walczyć z problemem nadużywania modelu sztucznej inteligencji wypuszczając... inny model sztucznej inteligencji sprawdzający tekst. Miało to być remedium na problem pracy niesamodzielnej, a wyszedł krzywo przyklejony plaster na krwawiącą ranę.

Pomimo że ChatGPT został stworzony z myślą o konwersacjach w języku naturalnym, młodzież na całym świecie szybko podchwyciła potencjał sztucznej inteligencji. Nie potencjał konwersacyjny, a jako źródło wsparcia przy pracy niesamodzielnej.
Co bystrzejsi dydaktycy szybko zaczęli działać na własną rękę i korzystać z dostępnych już rozwiązań takich jak OpenAI GPT-2 Output Detector Demo, GPTZeroX czy DetectGPT. Niektóre jednostki edukacyjne poszły o krok dalej, całkowicie blokując dostęp uczniom do domen należących do OpenAI.
Problem pracy niesamodzielnej, żeby nie powiedzieć plagiatów, jest na tyle poważny, że OpenAI zdecydowało się właśnie udostępnić kolejne narzędzie pozwalające być o krok przed osobami wykorzystującymi możliwości chatbota. AI Text Classifier to narzędzie pozwalające sprawdzić pochodzenie tekstu: czy został on napisany przez SI, czy przez człowieka.
Sztuczna inteligencja do walki ze sztuczną inteligencją. To walka na papierowe miecze
Jednak warto tu zauważyć, że chcąc być jeden krok przed osobami postępującymi niezbyt etycznie, można się naprawdę mocno potknąć. Jak przyznaje samo OpenAI, choć ulepszony względem poprzednich tego typu narzędzi, klasyfikator nie jest w pełni wiarygodny, a jego trafność w identyfikacji pochodzenia tekstu rośnie wraz z długością analizowanego tekstu.
Ponadto klasyfikator ma pewne ograniczenia. Tekst analizowany przez AI Text Classifier musi mieć długość przynajmniej 1000 znaków, powinien być w języku angielskim, ponieważ analizy tekstów we wszystkich innych językach dają "znacznie gorsze wyniki". Co więcej, klasyfikator można oszukać poprzez edycję tekstu wygenerowanego przez SI. Twórcy modelu odradzają używanie go do analizy kodu programów i aplikacji komputerowych, gdyż AI Text Classifier wykazuje niską skuteczność w ich poprawnej identyfikacji.
Jak podaje OpenAI, AI Text Classifier jest modelem sztucznej inteligencji dostrojonym na zbiorze danych składającym się z par tekstów napisanych przez ludzi i tekstów napisanych przez sztuczną inteligencję na ten sam temat. "Ludzka" część danych treningowych to teksty różnego pochodzenia, które według OpenAI "zostały napisane przez ludzi". Z kolei teksty napisane przez sztuczną inteligencję pochodzą zarówno od modeli OpenAI, jak i modeli opracowanych przez inne organizacje.
AI Text Classifier w praktyce
Aby sprawdzić, jak efektywny jest AI Text Classifier, wykonałam trzy próby z trzema różnymi zapytaniami, z którymi na jednym z etapów nauczania zderzył się każdy z nas. Klasyfikator ocenia każdy tekst w skali od 1 do 5, która jest reprezentowana przez słowne sformułowania: very unlikely, unlikely, unclear if it is, possibly i likely. Można je przetłumaczyć jako bardzo nieprawdopodobne, nieprawdopodobne, niejasne, możliwe i prawdopodobne.
W pierwszej próbie zapytałam ChatGPT o to, dlaczego Antygona była postacią tragiczną. Nie poprawiałam tekstu wygenerowanego przez chatbota w żaden sposób, jednakże generowałam go trzykrotnie by stworzyć wymagane przez klasyfikator 1000 znaków.
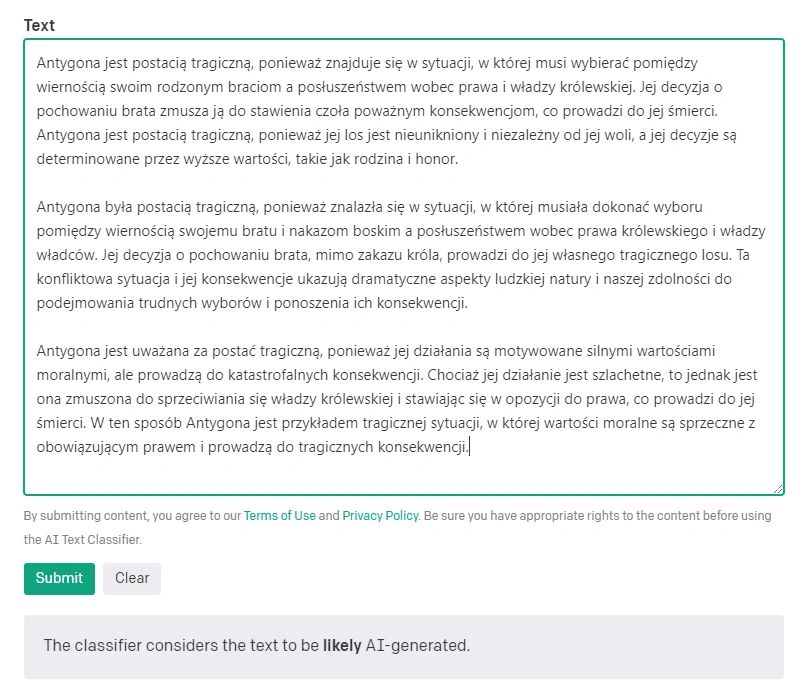
Klasyfikator poprawnie zaklasyfikował tekst jako "prawdopodobnie" wygenerowany przez sztuczną inteligencję.
Podnoszę poprzeczkę i edytuję wypowiedź SI
W drugiej próbie postawiłam przed modelem pytanie "Czego dokonał Jan Gutenberg, w którym roku i dlaczego jest to ważne?".
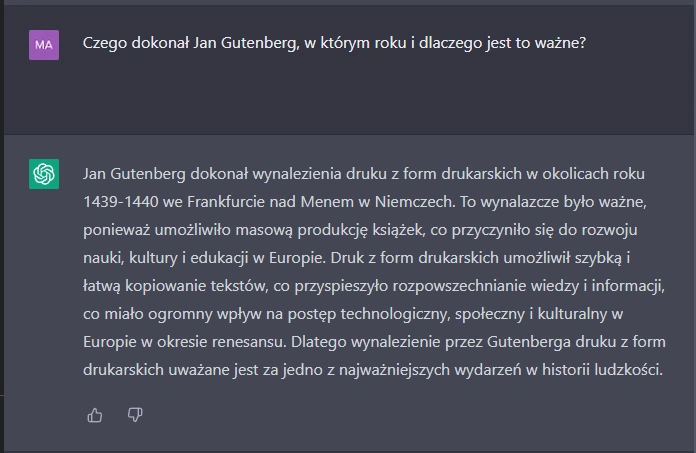
W tym przypadku pokusiłam się o dokonanie małych poprawek, które urozmaiciły i wydłużyły wypowiedź. Tak zmieniony tekst dałam do analizy AI Text Classifier.
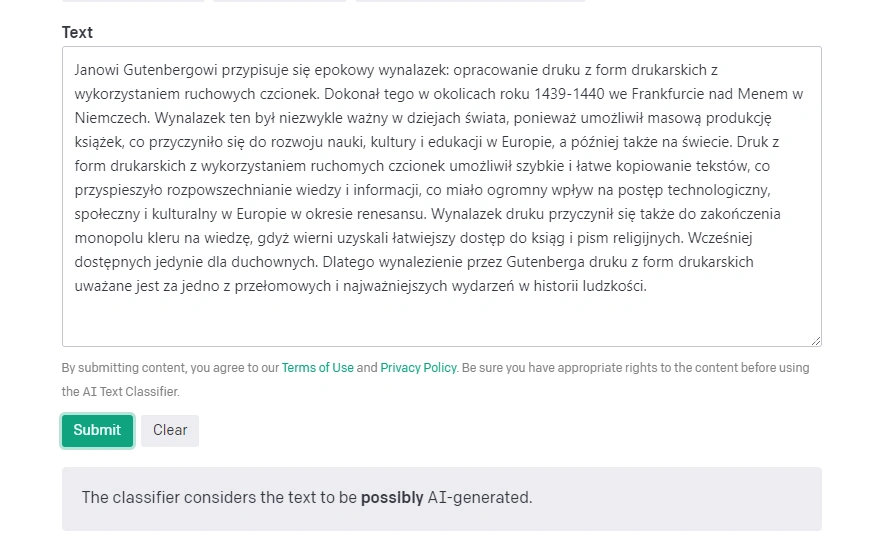
I tu spełniają się zapowiedzi OpenAI: klasyfikator nie jest pewny pochodzenia tekstu, uważając go za "możliwie wygenerowany przez SI".
Wystarczyły trzy próby, żeby przybić klasyfikator do muru
Trzecim testem było przepuszczenie przez klasyfikator autorskiego tekstu w języku angielskim na poziomie maturalnym. Tematem tekstu była osoba, którą podziwiam, a tekst od początku do końca został napisany przeze mnie. Celowo podjęłam się próby w języku angielskim, gdyż jest to natywny język modelu, w którym wykazuje on największy potencjał.
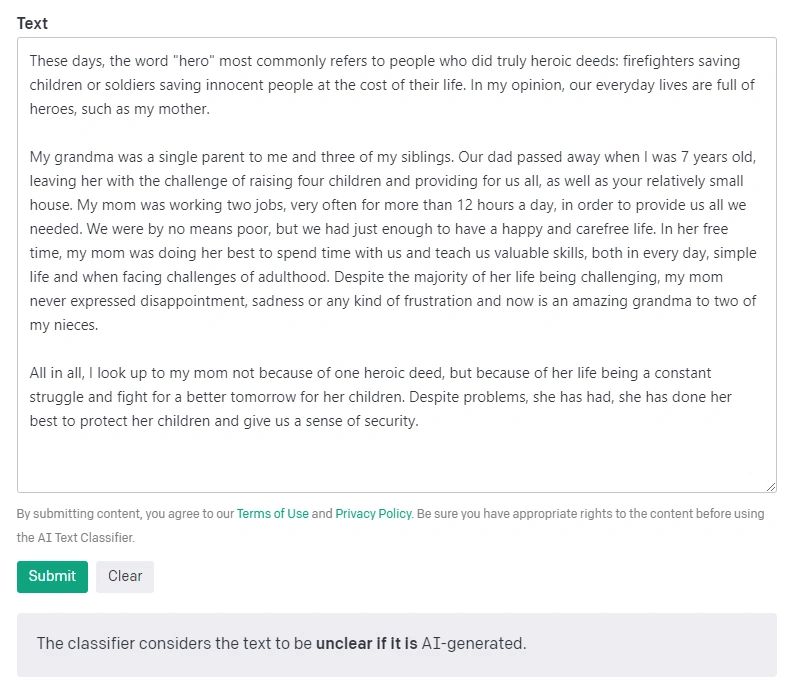
Jednak w tym przypadku - w scenariuszu, w którym AI Text Classifier powinien wykazać największą skuteczność, nie potrafił jednoznacznie wskazać czy tekst pochodzi od sztucznej inteligencji, czy nie.
AI Text Classifier będzie się z czasem uczyć i zapewne będzie dopracowywany, ale na razie jest jedynie odpadającym plastrem przyklejonym na krwawiącą ranę. Póki co, jest on niezwykle ograniczony i nie potrafi wykonać swej pracy na polu, na którym według twórców ma osiągać zadowalające wyniki. Nie potępiam idei, gdyż ogólnodostępny klasyfikator jest potrzebny, lecz upłynie jeszcze sporo czasu, zanim będzie można z niego skorzystać z czystym sumieniem.