Ile liter jest w wyrazie truskawka? Wyjaśniamy, czy AI jest tak głupia, na jaką się kreuje
"Ile jest liter w wyrazie "strawberry"? To pytanie podbiło internet, stając się argumentem do żartów z właściwie każdego dostępnego modelu generatywnej sztucznej inteligencji. My też się śmiejemy, ale i wyjaśniamy, dlaczego żarty i memy wkrótce po prostu się znudzą.

Przez ostatnie tygodnie w internecie i każdym jego zakamarku przewinęły się zrzuty ekranu z najpopularniejszych czatbotów pokazujące jak duże modele językowe sztucznej inteligencji nie radzą sobie z liczeniem ilości liter "r" w słowie "strawberry" (ang. truskawka). Z perspektywy osoby mało obytej ze specyfiką działania generatywnej AI jest to na pewno niezwykle zabawne, bo mamy tendencję do antropomorfizacji i gloryfikacji sztucznej inteligencji, a tu ni z gruszki ni z pietruszki AI wywala się na pytaniu, na które z dumą odpowiada przedszkolak.
Jednak cały sęk w tym, że zadajemy czatbotom pytanie, na które nie mogą odpowiedzieć ze względu na specyfikę swojej architektury.
Ile jest "r" w wyrazie "truskawka"? Wyjaśniamy, dlaczego AI zawsze będzie się wywalać na tym pytaniu
Wszystkie czatboty, z którymi aktywnie konwersujemy (lub o których czytasz każdego dnia) - ChatGPT, Gemini, Copilot, Claude, Grok, oparte są na architekturze transformer, metodzie głębokiego uczenia zaprojektowanej przez inżynierów Google. W dużym uproszczeniu, gdy do dużego modelu językowego (LLM) wprowadza się dane tekstowe, AI rozbija je na tokeny. Token może być słowem, częścią słowa, sylabą lub literą - zależnie od wielkości modelu, jego specyfiki i specyfiki języka (tj. naszego ludzkiego języka) którym operuje. Następnie każdemu tokenowi przypisuje identyfikator, czyli po prostu reprezentującą go liczbę. Sercem architektury transformer jest mechanizm uwagi (stąd też nazwa publikacji naukowców Google'a: "Attention is all you need" - "Uwaga to wszystko, czego potrzebujesz"). Pozwala on modelowi skupić się na różnych częściach tekstu wejściowego podczas tworzenia przewidywań tekstu - czyli po prostu generowania pożądanej przez nas odpowiedzi. W efekcie pozwala to AI na "ważenie" (niczym ocen w szkole) znaczenie każdego tokena w stosunku do innych, a tym samym wygenerowanie ciągu tokenów, które "zdaniem" sieci neuronowej najlepiej pasują do zapytania. A z naszej perspektywy tokeny to - ponownie - słowa, części słowa, sylaby, litery, po prostu tekst.
T-r-u-s-k-a-w-k-a
Teraz spójrzmy na słowo strawberry z perspektywy ludzkiej i modelu GPT-4 (przykładowo). My widzimy je jako ciąg 10 liter: s-t-r-a-w-b-e-r-r-y. GPT3.5 turbo oraz GPT-4 widzą je jako ciąg trzech tokenów: st-raw-berry oznaczonych identyfikatorami 496 - 675 - 15717. I teraz sęk w tym, że GPT3.5 turbo oraz GPT-4 (lub jakikolwiek inny model) w ogóle nie widzą liter. AI widzi tylko identyfikatory tokenów oraz częstotliwość ich występowania obok siebie. Kiedy my wpisujemy "strawberry", GPT-4 automatycznie tłumaczy sobie słowo na tokeny 496 - 675 - 15717. Dzięki danym treningowym (które pokazują modelowi jak często dane słowa=tokeny występują razem w języku naturalnym) skojarzy trzy tokeny z trzema innymi tokenami - 374 - 264 - 14098, które odpowiadają wyrażeniu "is a fruit" ("to owoc"), może skojarzyć z tokenem 95928 - słowo "sweet" ("słodki") lub tokenem 1171 - słowo "red" ("czerwony"). Ale nadal to operowanie tokenami, a nie słowami czy literami.
Kiedy wpisujemy zapytanie "how many r's in strawberry", sztuczna inteligencja rozbija całe zapytanie i myśli o wszystkich tokenach, które często występują w towarzystwie 496 - 675 - 15717. AI dosłownie przez moment "zamyka się w sobie" i "myśli" o słowie truskawka i towarzyszących jej tokenach=słowach: o morfologii gatunku, zastosowaniach, wyglądzie, uprawie, o wszystkich tokenach=słowach, które je opisują. I nie znajduje tokenów, które byłyby o wadze na tyle dużej, by móc je z całą pewnością połączyć z zapytaniami o "litery" i "truskawki. A tam, gdzie brakuje danych, AI zaczyna wymyślać. Stąd dowiadujemy się, że w słowie strawberry mamy tylko jedno lub dwa "r".
Na swój sposób można to porównać do sytuacji, w której układamy obrazek z puzzli. My ludzie widzimy zarówno obrazek ("truskawkę") jak i elementy układanki, które składają się na całość obrazka (litery "t-r-u-s-k-a-w-k-a"). Z kolei AI "widzi" jedynie obrazek przedstawiający truskawkę, nie widząc elementów układanki. Dlatego strzela i liczy, że daje nam pożądaną odpowiedź.
W przypadku słowa strawberry i kontekście modeli multimodalnych (czyli akceptujących nie tylko tekst jako dane wejściowe, ale także głos, dźwięki czy obrazy) występuje także dość ciekawa sytuacja. Bowiem te muszą utożsamiać tokeny z danymi tekstowymi z tokenami zawierającymi dane dźwiękowe. Tłumaczenie na ludzki: pisownię z wymową. W angielskiej wymowie słowa "strawberry" r występuje dwa razy, dlatego ChatGPT może się upierać przy dwóch literach "r", bo jego dane zebrane wokół tokenów 496 - 675 - 15717 uwzględniają wymowę, a która z kolei zawiera dwa dźwięczne "r" (lub jak kto woli, dwa dźwięczne 81).
Myślenie tokenami
Tokenowość "myślenia" naszych ulubionych czatbotów można zaobserwować także każąc im napisać wspak słowa z błędami. Teraz bardziej przyziemnie - słowo przyziemny. Narzędzie gpt-tokenizer playground pozwala w prosty sposób zwizualizować jak model GPT-4o "rozbija słowo" na tokeny.
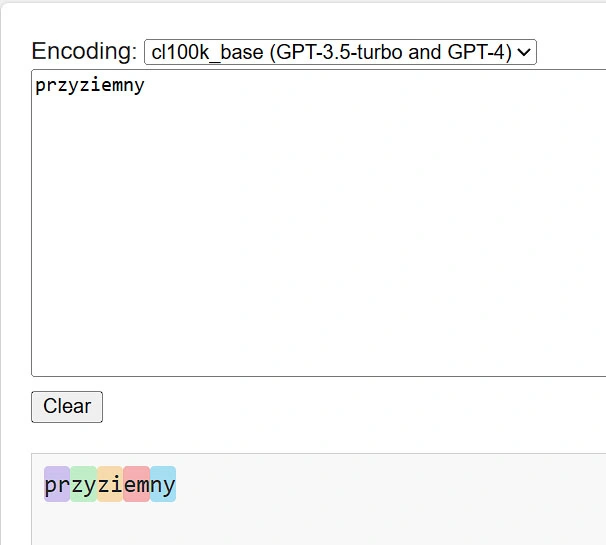
W odpowiedzi na moją prośbę ChatGPT (na modelu GPT-4o mini) wykonał zadanie i przekazał, że "przyziemny" wspak pisane jest jako "ynmiezyrp". Jeżeli masz oczopląs to spieszę z pomocą i odwróceniem kolejności liter: "pryzeimny".
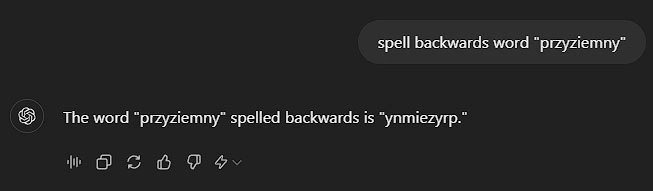
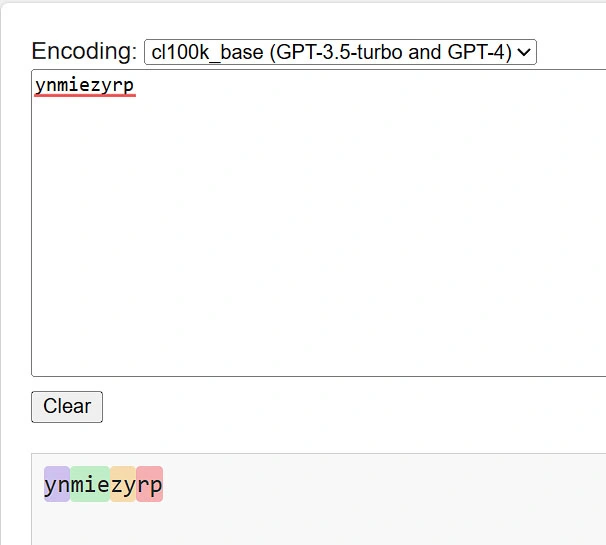
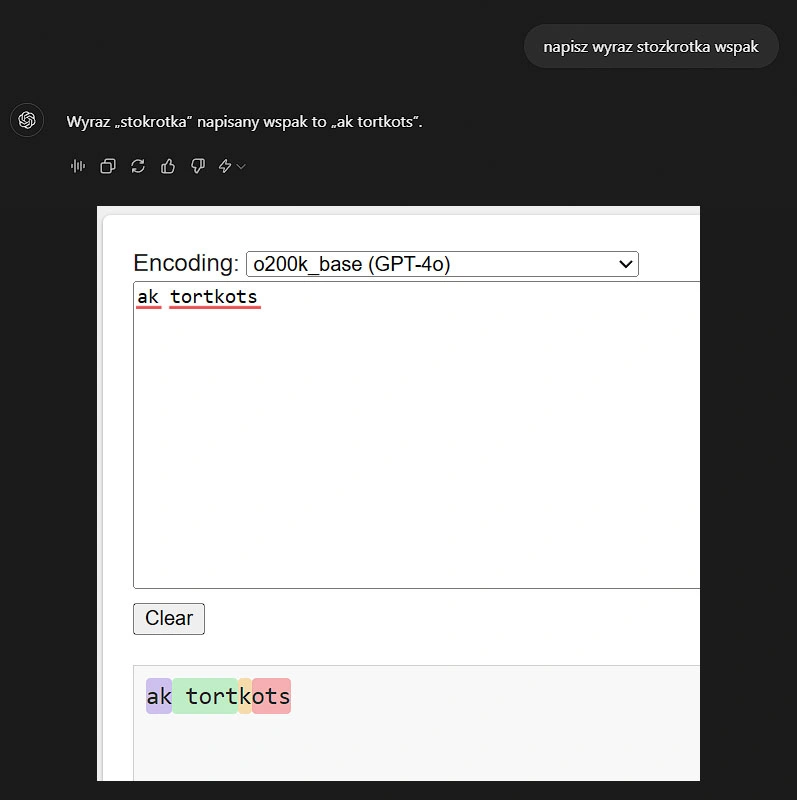
Jak widać, LLM nawet literując wspak nie myśli o pojedynczych literach, a próbuje przypisać ciąg podobnych tokenów, w efekcie gubiąc się i tworząc "kwiatki".
Choć ów żarty z generatywnej sztucznej inteligencji mają całkiem poważne wyjaśnienie, to nie ma nic złego w śmianiu się ze wpadek generatywnej AI. U mnie samej testowanie różnych promptów i słów wywołałao niemałego banana na twarzy. I myślę, że sam Sam Altman zdaje sobie sprawę z uroku ograniczeń technologii, której jest maskotką.