Trwa jedna z większych awarii w historii. Ale były większe. Lista TOP 9 katastrof komputerowych
Niedziałające firmy, banki i lotniska to dla wielu Polaków słuszny powód do frustracji. Nic jednak nie poprawia tak dobrze humoru jak inni mieli gorzej. Zatem: służymy.

Dzisiejsza globalna awaria komputerów to jedna z groźniejszych awarii w historii całej informatyki. Groźna z uwagi na niesione za sobą skutki: paraliż rozmaitych instytucji negatywnie wpływa na ekonomię i gospodarkę, w skrajnych przypadkach stanowiąc poważne zagrożenie dla niektórych firm czy nawet osób indywidualnych. Wszystko przez wadliwą aktualizację do popularnego rozwiązania mającego, o ironio, chronić komputery przed sieciowymi zagrożeniami.
Wpadka firmy Crowdstrike i pośrednio Microsoftu zapisze się więc w annałach historii. Tym niemniej nie ona jedna. Prawdę rzekłszy jest wręcz trywialnym problemem w porównaniu do niektórych innych katastrof w historii informatyki. My przypomnimy te największe (lub najbardziej medialne). A są to:
Błąd roku 2000 (Y2K)
Błąd roku 2000, znany również jako Y2K lub pluskwa milenijna, był problemem informatycznym, który wywołał globalne problemy na przełomie tysiąclecia. Wiele systemów komputerowych zapisywało daty, używając tylko dwóch ostatnich cyfr roku, co miało potencjalnie prowadzić do błędów w obliczeniach dat po 31 grudnia 1999 r. Przykładowo, rok 2000 mógł być błędnie interpretowany jako 1900, co groziło zakłóceniem działania systemów bankowych, energetycznych, transportowych i innych kluczowych dla funkcjonowania społeczeństwa.
W odpowiedzi na te obawy, przedsiębiorstwa i instytucje na całym świecie podjęły szeroko zakrojone działania naprawcze. Aktualizacje oprogramowania, testy systemów i modyfikacje sprzętu były przeprowadzane w pośpiechu, aby zapobiec potencjalnym awariom. Koszty tych działań były ogromne, szacuje się, że globalnie mogły wynieść od 400 mld do 600 mld dol. Mimo to, wiele osób gromadziło zapasy żywności i wody, a niektórzy nawet wypłacali duże sumy gotówki z banków w obawie przed komputerowym Armagedonem.
Ostatecznie, 1 stycznia 2000 r., przewidywana apokalipsa informatyczna nie nastąpiła. Wielu ekspertów uważa, że to właśnie dzięki podjętym działaniom prewencyjnym uniknięto większych problemów. Choć odnotowano pewne drobne incydenty, nie doszło do katastroficznych awarii. Prezydent USA, Bill Clinton, nazwał Y2K pierwszym wyzwaniem XXI wieku, które zostało pomyślnie pokonane, a retrospekcje tego wydarzenia często chwalą programistów, którzy pracowali nad uniknięciem przewidywanej katastrofy.
Awaria sieci AT&T
Awaria sieci AT&T z 1990 r. jest jednym z najbardziej znaczących zdarzeń w historii telekomunikacji. 15 stycznia 1990 r., w wyniku błędu oprogramowania w systemach przełączających Number 4 ESS (Electronic Switching System), doszło do rozległej awarii w sieci długodystansowej AT&T. Błąd ten spowodował wyłączenie wielu przełączników w całej sieci, co doprowadziło do niemożności połączenia się prawie połowy prób wykonywanych przez użytkowników. Awaria ta była szczególnie niepokojąca, ponieważ AT&T miało reputację niezawodności i bezpieczeństwa, a ich systemy były uważane za wzór stabilności.
Problem rozpoczął się od usterek wewnętrznych w jednym z urządzeń interfejsu tronkowego, które poinformowało przełącznik w Nowym Jorku o swoich problemach. Standardowy kod naprawczy miał za zadanie zainicjować ponowne uruchomienie urządzenia, co miało trwać od czterech do sześciu sekund. W tym czasie nowe połączenia były blokowane. Po pomyślnym zresetowaniu, przełącznik w Nowym Jorku wrócił do pracy, ale wtedy ujawnił się błąd w nowym oprogramowaniu. W poprzednim systemie, przełącznik A wysyłał wiadomość, że ponownie działa, a przełącznik B podwójnie sprawdzał, czy A jest ponownie w służbie. Z nowym oprogramowaniem, przełącznik A zaczął przetwarzać połączenia i wysyłać sygnały routingu połączeń. Pojawienie się ruchu z przełącznika A miało informować przełącznik B, że A ponownie działa.
Niestety, kiedy przełącznik B otrzymał drugą próbę połączenia od A podczas resetowania swojej wewnętrznej logiki, doszło do zamieszania. Oprogramowanie zostało karmione dziwnymi danymi i próbowało wykonać instrukcję, która nie miała sensu. Oprogramowanie poinformowało przełącznik B, że jego procesor CCS7 jest wadliwy, co skłoniło przełącznik B do wyłączenia się, aby uniknąć rozprzestrzeniania problemu. Niestety, przełącznik B następnie wysłał wiadomość do innych przełączników, że jest wyłączony i nie przyjmuje dodatkowego ruchu. Gdy przełącznik B zresetował się i zaczął ponownie działać, wysłał wiadomości o przetwarzaniu połączeń przez łącze CCS7. Cała sytuacja doprowadziła do tego, że przez dziewięć godzin, prawie 50 proc. połączeń telefonicznych przez AT&T nie zostało zrealizowanych, a sama AT&T straciła ponad 60 mln dol. z powodu niepołączonych rozmów.
Wirus ILOVEYOU
Wirus ILOVEYOU, znany również jako Love Bug lub Love Letter, to jeden z najbardziej destrukcyjnych robaków komputerowych w historii cyberbezpieczeństwa. Po raz pierwszy pojawił się 4 maja 2000 r. i błyskawicznie rozprzestrzenił się na całym świecie, wykorzystując książki adresowe programu Microsoft Outlook do wysyłania swoich kopii do kontaktów ofiary. Wirus ten był napisany w języku VBScript i miał postać skryptu, co ułatwiało hakerom tworzenie jego mutacji. Większość z tych mutacji posiadała jednak niewielkie zmiany, najczęściej w treści wiadomości e-mail i nazwach plików.
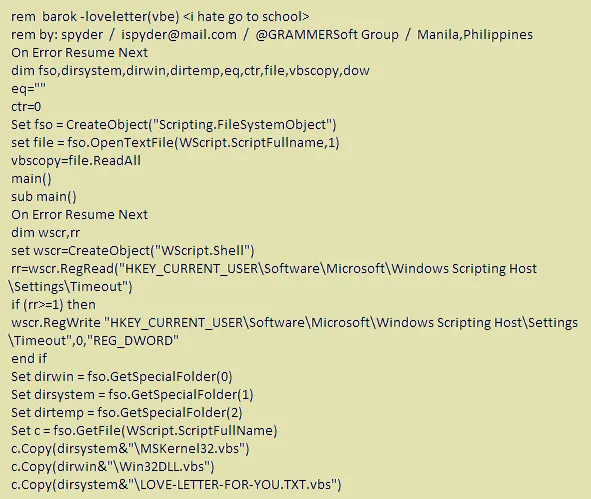
Mechanizm działania wirusa ILOVEYOU polegał na prostym, ale skutecznym wykorzystaniu inżynierii społecznej. Wirus przybierał formę niewinnego e-maila z tematem ILOVEYOU i załącznikiem LOVE-LETTER-FOR-YOU.TXT.vbs. Gdy niczego niepodejrzewający odbiorca otwierał załącznik, skrypt VBScript był wykonywany, nadpisywał różne typy plików, takie jak JPEG i MP3, i wysyłał kopie wirusa do wszystkich kontaktów w książce adresowej. To doprowadziło do szybkiego rozprzestrzeniania się i znacznych zakłóceń w działaniu systemów informatycznych. Wirus nadpisywał ważne pliki użytkownika swoją kopią, co w wielu przypadkach prowadziło do trwałej utraty danych.
Skutki infekcji wirusem ILOVEYOU były ogromne. Szacuje się, że spowodował on straty w wysokości około 10 mld dol. na całym świecie. Wirus zmusił wiele dużych organizacji, w tym Pentagon, CIA i Parlament Brytyjski, do wyłączenia swoich serwerów e-mail w celu powstrzymania rozprzestrzeniania się infekcji. Ta sytuacja uwypukliła krytyczną potrzebę stosowania solidnych środków cyberbezpieczeństwa i podniosła świadomość na temat niebezpieczeństw związanych z inżynierią społeczną i atakami phishingowymi.
Awaria Amazon Web Services
Awaria Amazon Web Services (AWS) z 28 lutego 2017 r. była znaczącym zdarzeniem, które uświadomiło wiele firm i użytkowników o zależności od usług chmurowych. Problem rozpoczął się od błędu ludzkiego, kiedy to pracownik Amazona podczas rutynowej konserwacji wprowadził niepoprawnie komendę, co spowodowało wyłączenie większej liczby serwerów niż planowano. Skutkiem tego była reakcja łańcuchowa, która doprowadziła do przestojów w działaniu kluczowych systemów AWS, w tym Amazon Simple Storage Service (S3), który jest podstawą dla wielu stron internetowych i aplikacji.
W wyniku tej awarii, wiele popularnych serwisów internetowych, takich jak Slack, Quora, a nawet amerykańska komisja papierów wartościowych i giełd, doświadczyło poważnych problemów z działaniem. Niektóre strony ładowały się bardzo powoli, inne w ogóle nie były dostępne. Nawet panel Amazona, który służy do powiadamiania użytkowników o funkcjonowaniu usług firmy, przestał działać. To pokazało, jak jedno niewielkie pomyłki mogą mieć ogromny wpływ na działanie połowy Internetu i jak ważne jest posiadanie solidnych procedur awaryjnych.
Amazon szybko zareagował na problem, wdrożył nowe przepisy bezpieczeństwa i przywrócił działanie serwerów. Mimo to, awaria ta stała się przestrogą dla całej branży IT i podkreśliła potrzebę dywersyfikacji i redundancji w infrastrukturze chmurowej. Zdarzenie to również przyczyniło się do wzrostu świadomości na temat potencjalnych ryzyk związanych z centralizacją usług i danych w chmurze, a także znaczenia szybkiego reagowania i komunikacji w przypadku wystąpienia awarii.
Czytaj też:
Awaria systemu operacyjnego Blackberry
Awaria systemu operacyjnego BlackBerry w październiku 2011 r. była jednym z największych zakłóceń w historii usług mobilnych. Problem dotknął użytkowników na całym świecie, powodując trzydniową przerwę w dostępie do kluczowych funkcji smartfonów BlackBerry, w tym do poczty e-mail, przeglądania Internetu i usług BlackBerry Messenger (BBM). Awaria ta miała miejsce w krytycznym momencie dla firmy Research In Motion (RIM), producenta BlackBerry, który już walczył z rosnącą konkurencją ze strony iPhone'ów Apple i urządzeń z systemem Android.
Przyczyną awarii była usterka w głównym centrum danych RIM w Slough, w Wielkiej Brytanii. Problem rozpoczął się od awarii routera, ale szybko przekształcił się w poważniejsze zakłócenie, gdy systemy zapasowe nie zadziałały jak należy. To doprowadziło do nagromadzenia danych, które zablokowały system. W rezultacie, miliony użytkowników BlackBerry w Europie, na Bliskim Wschodzie, w Afryce, a później także w Ameryce Północnej i Południowej, doświadczyły znacznych problemów z komunikacją. Ta globalna przerwa w działaniu usług była szczególnie frustrująca dla użytkowników, którzy polegali na swoich urządzeniach do prowadzenia biznesu i osobistej komunikacji.
Reakcja RIM na tę awarię była szeroko krytykowana. Firma początkowo nie dostarczała regularnych aktualizacji ani szczegółowych informacji o przyczynach problemu i oczekiwanym czasie przywrócenia usług. To spowodowało niepewność i niezadowolenie wśród klientów oraz zaszkodziło reputacji firmy jako niezawodnego dostawcy usług komunikacyjnych. Ostatecznie, RIM przywrócił pełną funkcjonalność usług, ale awaria ta była jednym z czynników, które przyczyniły się do dalszego spadku udziału BlackBerry na rynku smartfonów. Wydarzenie to podkreśliło również znaczenie redundancji systemów i szybkiej, przejrzystej komunikacji w przypadku awarii technologicznych.
Błąd w Intel Pentium
Błąd w procesorach Intel Pentium z 1994 r., znany jako błąd FDIV, był jednym z najbardziej znanych błędów w historii technologii. Odkryty przez Thomasa R. Nicely'ego, profesora matematyki, błąd ten dotyczył jednostki zmiennoprzecinkowej (FPU) wczesnych procesorów Pentium i powodował, że procesor zwracał nieprawidłowe wyniki binarnych obliczeń zmiennoprzecinkowych przy dzieleniu niektórych par liczb o wysokiej precyzji. Chociaż błąd występował rzadko i w większości przypadków prowadził do niewielkich odchyleń od poprawnych wartości, w pewnych okolicznościach mógł wystąpić częściej i prowadzić do znaczniejszych błędów.

Błąd FDIV był wynikiem brakujących wartości w tabeli wyszukiwania używanej przez algorytm dzielenia zmiennoprzecinkowego FPU, co prowadziło do małych błędów w obliczeniach. W ekstremalnych przypadkach błąd mógł osiągnąć czwartą znaczącą cyfrę wyniku, chociaż było to rzadkie. Zazwyczaj błąd ograniczał się do dziewiątej lub dziesiątej cyfry po przecinku. Pewne kombinacje licznika i mianownika uruchamiały błąd, na przykład dzielenie 4 195 835 przez 3 145 727. Wykonanie tego obliczenia w dowolnym oprogramowaniu wykorzystującym koprocesor zmiennoprzecinkowy, takim jak Kalkulator Windows, pozwalało użytkownikom odkryć, czy ich chip Pentium był dotknięty problemem.
Reakcja Intela na błąd FDIV była początkowo krytykowana, ponieważ firma minimalizowała problem, twierdząc, że jest on nieistotny dla większości użytkowników. Jednak po wzroście presji ze strony społeczności technologicznej i mediów, Intel zdecydował się na pierwsze w historii pełne wycofanie chipa komputerowego. W grudniu 1994 r. firma ogłosiła program wymiany procesorów dla użytkowników, którzy mogli wykazać, że błąd wpływa na ich pracę. W swoim rocznym raporcie z 1994 r., Intel poinformował, że poniósł koszt przed opodatkowaniem w wysokości 475 mln dol. (…) na pokrycie kosztów wymiany i utylizacji tych mikroprocesorów. To wydarzenie stało się ważną lekcją dla całej branży technologicznej, podkreślając znaczenie dokładnego testowania i odpowiedzialności za jakość produktów.
Awaria GitHub
Awaria GitHuba z 2018 r. była jednym z największych ataków typu Distributed Denial of Service (DDoS), jakie kiedykolwiek dotknęły jakąkolwiek platformę internetową. Miała miejsce 28 lutego i osiągnęła szczytowy ruch sieciowy na poziomie 1,35 terabitów na sekundę, co było wówczas rekordem dla ataków DDoS. Atak wykorzystał słabość w systemach memcached, które są powszechnie używane do przyspieszania dostępu do danych poprzez buforowanie. Z powodu błędnej konfiguracji, atakujący mogli wykorzystać te systemy do zwiększenia ilości danych wysyłanych do celu ataku, w tym przypadku serwerów GitHuba.
W wyniku ataku, strona GitHub.com była niedostępna od 17:21 do 17:26 UTC, a następnie dostępna z przerwami do 17:30 UTC. Atak pochodził z ponad tysiąca różnych systemów autonomicznych (ASNs) i obejmował dziesiątki tysięcy unikalnych punktów końcowych. W odpowiedzi na atak, inżynierowie GitHuba szybko podjęli działania, aby przekierować ruch przez Akamai, firmę specjalizującą się w usługach sieciowych, co pozwoliło na przywrócenie stabilności i dostępności serwisu.
To zdarzenie było ważnym przypomnieniem dla całej branży technologicznej o konieczności ciągłego monitorowania i aktualizacji konfiguracji systemów, aby zapobiegać podobnym atakom w przyszłości. GitHub, jako kluczowa platforma dla programistów i firm na całym świecie, podjął dodatkowe kroki w celu zabezpieczenia swojej infrastruktury przed przyszłymi atakami DDoS. Awaria ta pokazała również, jak ważne jest posiadanie planów awaryjnych i zdolności szybkiego reagowania w przypadku cyberataków.
Błąd w Google Cloud
Błąd w Google Cloud z 2019 r. był znaczącym incydentem, który wpłynął na wiele usług Google Cloud Platform (GCP). 24 września 2019 r. doszło do przeciążenia wewnętrznego systemu komunikacji typu publish/subscribe, co miało wpływ na różne produkty GCP, w tym Compute Engine, Kubernetes Engine, Cloud Build i Stackdriver Logging & Monitoring. Przeciążenie to spowodowało ograniczenia w operacjach administracyjnych dla wielu produktów, jednak istniejące obciążenia i instancje w większości przypadków nie były dotknięte. Incydent rozpoczął się o godzinie 12:46 czasu pacyficznego i zakończył o 20:00 tego samego dnia.
Rozwijając szczegółowo, Google App Engine (GAE) doświadczył problemów z tworzeniem, aktualizacją i usuwaniem operacji administracyjnych na całym świecie, co trwało przez 5 godzin i 24 minuty. Użytkownicy mogli napotkać komunikaty błędów takie jak APP_ERROR. Z kolei instancje Google Compute Engine (GCE) nie mogły zostać uruchomione w regionie us-central1-a przez 1 godz. i 21 min., a wewnętrzny DNS GCE doświadczał opóźnień w rozwiązywaniu nowo utworzonych nazw hostów. Ponadto, Google Kubernetes Engine (GKE) miał opóźnienia w metadanych zasobów i niedokładne monitorowanie Stackdriver dla metryk klastra.
Google przeprosił klientów, których usługi zostały dotknięte tym incydentem, i podjął natychmiastowe kroki w celu poprawy wydajności i dostępności platformy. Ten incydent podkreślił znaczenie solidnej architektury systemów informatycznych i konieczność posiadania planów awaryjnych oraz procedur szybkiego reagowania na podobne sytuacje w przyszłości. Pokazał również, jak ważna jest ciągła weryfikacja i aktualizacja konfiguracji systemów, aby zapobiegać przeciążeniom i innym problemom, które mogą zakłócić działanie usług chmurowych.
Awaria Sony PlayStation Network
Awaria Sony PlayStation Network (PSN) w kwietniu 2011 r. była jednym z największych naruszeń bezpieczeństwa danych w historii gier online. Atak hakerski na infrastrukturę PSN doprowadził do wyłączenia sieci na 23 dni i naruszenia danych osobowych około 77 mln kont użytkowników. Użytkownicy konsol PlayStation 3 i PlayStation Portable zostali pozbawieni dostępu do usług online, co wywołało ogromne niezadowolenie wśród społeczności graczy i zaniepokojenie w kwestii ochrony prywatności.
W wyniku ataku, hakerzy uzyskali dostęp do wrażliwych danych, w tym nazw użytkowników, haseł, adresów e-mail, dat urodzenia oraz informacji o kartach kredytowych. Sony zostało skrytykowane za opóźnienie w informowaniu użytkowników o naruszeniu i potencjalnym zagrożeniu dla ich danych osobowych. Firma podjęła kroki w celu wzmocnienia bezpieczeństwa, w tym tymczasowe wyłączenie PSN, przeprowadzenie dogłębnej analizy bezpieczeństwa oraz współpracę z ekspertami zewnętrznymi w celu zidentyfikowania i naprawienia luk w zabezpieczeniach.
Ostatecznie, Sony przywróciło działanie PSN, wprowadzając szereg ulepszeń bezpieczeństwa i oferując użytkownikom program Welcome Back jako rekompensatę za niedogodności. Program ten obejmował darmowe gry i subskrypcje, a także dodatkowe środki ochrony tożsamości dla osób potencjalnie dotkniętych naruszeniem. Awaria PSN była drogocenną lekcją dla całej branży gier online, podkreślając znaczenie cyberbezpieczeństwa i szybkiej reakcji na incydenty związane z bezpieczeństwem danych.