Elon Musk odpala nowego Groka. Trzeba przyznać, że jest tani
Najbardziej „medialny” multimiliarder nie zwalnia tempa. Jego xAI odpala Grok 4.3 i… bardzo tanio sprzedaje całkiem zaawansowane funkcje.

Gdy Elon Musk walczy w sądzie z Samem Altmanem i OpenAI jego druga wojna - ta o rynek modeli AI - trwa w najlepsze. xAI właśnie wypuściło Groka 4.3, czyli nową wersję swojego dużego modelu językowego oraz cały pakiet narzędzi głosowych z zaawansowanym klonowaniem głosu. I choć pod względem „czystej mocy” Grok 4.3 wciąż nie jest królem benchmarków to w jednym obszarze uderza wyjątkowo mocno: w cenę.
To jest ruch w stylu Muska: niekoniecznie najładniejsze, niekoniecznie najbardziej dopieszczone, ale agresywnie wycenione i nastawione na konkretne zastosowania. I to takie, które mogą zainteresować nie tylko wielkie korporacje, ale też startupy, software house’y, a nawet ambitnych twórców aplikacji.
Czytaj też:
Grok 4.3 to model, który „zawsze myśli”
xAI chwali się, że nowy model ma „always-on reasoning” - czyli w praktyce: zawsze uruchamia rozumowanie zanim odpowie. Nie ma tu przełącznika „więcej myślenia / mniej myślenia”, nie ma trybu „szybko, ale płytko”. Grok 4.3 ma z definicji najpierw „pomyśleć”, potem mówić. W praktyce oznacza to, że model generuje wewnętrzne „łańcuchy myśli” (których użytkownik nie widzi) zanim wygeneruje finalną odpowiedź. To podejście jest coraz popularniejsze wśród topowych modeli - ale xAI idzie krok dalej i robi z tego domyślny tryb pracy.
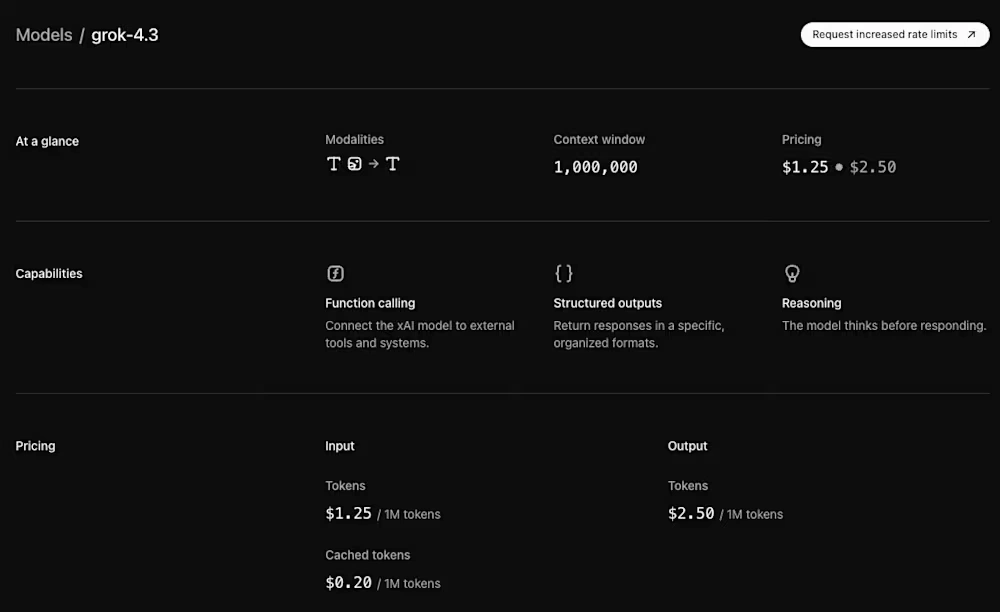
Jest też drugi, bardzo konkretny parametr: kontekst. Grok 4.3 obsługuje okno kontekstu na poziomie miliona tokenów. To kilka grubych książek albo cały kod średniej wielkości aplikacji, albo ogromny pakiet dokumentów prawnych. Oczywiście xAI nie robi tego charytatywnie - powyżej 200 tys. tokenów wchodzi wyższa stawka za „wysoki kontekst”. Ale sam fakt, że model jest w stanie utrzymać spójność na takiej objętości danych jest istotny.
Grok 4.3 przyjmuje tekst i obrazy, a na wyjściu generuje tekst. Jest też wyraźnie optymalizowany pod tzw. agentów - czyli scenariusze, w których AI nie tylko odpowiada na pytania, ale wykonuje zadania: korzysta z narzędzi, generuje pliki, przetwarza dane, buduje raporty. Model potrafi:
- wygenerować złożony arkusz Excela z wieloma zakładkami, formułami i dashboardem
- tworzyć sformatowane PDF-y, np. 12-stronicowe raporty o produktach SpaceX, z logotypami, grafikami i tabelami,
- projektować prezentacje PowerPoint, np. 9-slajdowe decki z określoną strukturą, z macierzami decyzyjnymi i nawet wplecionym humorem.
Grok jako cyfrowy pracownik, nie tylko gadatliwy bot
xAI buduje wokół Groka 4.3 cały ekosystem narzędzi, które model może samodzielnie wywoływać. Grok 4.3 ma dostęp m.in. do:
- wyszukiwarki internetowej i wyszukiwarki X (dawnego Twittera) - może przeglądać sieć i posty na X, żeby omijać swój knowledge cutoff (który jest ustawiony na grudzień 2025),
- środowiska do wykonywania kodu w Pythonie - może liczyć, przetwarzać dane, robić analizy,
- systemu RAG - może przeszukiwać kolekcje dokumentów i pliki użytkownika.
To wszystko jest spięte po stronie serwera, więc z punktu widzenia dewelopera Grok ma być agentem, który sam decyduje kiedy odpalić wyszukiwarkę, kiedy policzyć coś w Pythonie, a kiedy sięgnąć do dokumentów. To dokładnie ten sam kierunek, w którym idą OpenAI, Anthropic, Google i cała reszta. Różnica polega na tym, że xAI próbuje to sprzedać jako „cyfrowego pracownika w wersji value”: może nie najinteligentniejszego w każdej dziedzinie, ale za to bardzo taniego w utrzymaniu.
Custom Voices, klonowanie i tani voice agent
Drugi filar ogłoszenia xAI to głos. Firma odpala Custom Voices - system klonowania głosu oraz powiązane API do Text-to-Speech, Voice Agent i Speech-to-Text. Custom Voices pozwala sklonować głos na podstawie próbki trwającej zaledwie około 120 sekund. W praktyce wygląda to tak: użytkownik wchodzi do webowego kreatora, czyta kilka losowych fragmentów tekstu, a po chwili dostaje „swoją” sztuczną wersję.
xAI podkreśla, że model nie kopiuje tylko barwy, ale też styl mówienia. Jeśli nagrasz próbkę w tonie uprzejmego konsultanta infolinii to wygenerowany głos będzie mówił w podobnym, „pomocnym” stylu. To jest dokładnie ten poziom dopasowania, który interesuje firmy budujące boty głosowe, automatyczną obsługę klienta czy personalizowane asystenty.
Są też ograniczenia. Custom Voices jest dostępne tylko w Stanach Zjednoczonych, z wyłączeniem Illinois – ze względu na lokalne regulacje dotyczące danych biometrycznych i prywatności. Programistyczny dostęp do endpointu /v1/custom-voices jest na razie zarezerwowany dla klientów Enterprise. W konsoli webowej można jednak tworzyć do 30 głosów na raz, a każdy z nich można jednym kliknięciem usunąć.
Na tym nie koniec. xAI wprowadza Voice Agent API (model grok-voice-think-fast-1.0), rozliczany w prosty sposób: 3 dolary za godzinę interakcji głos-głos, czyli około 0,05 dol. za minutę. To stawia Groka mniej więcej w dolnej-środkowej części stawki, jeśli porównać go z innymi usługami głosowymi. Dla porządku: ElevenLabs potrafi kosztować kilkanaście dolarów za godzinę, OpenAI TTS w wersji HD - około 1,8 dol. za godzinę, a niektóre komercyjne plany idą jeszcze wyżej.
Do tego dochodzi klasyczne TTS (pięć gotowych głosów: Eve, Ara, Rex, Sal, Leo) za 4,20 dol. za milion znaków oraz STT (transkrypcja) - 0,20 dol. za godzinę w trybie streamingu i 0,10 dolara za godzinę w trybie batch. Jak na rynek enterprise, to są stawki, które trudno nazwać wygórowanymi.
Ceny: Grok 4.3 gra w lidze „tani, ale całkiem sprytny”
Przejdźmy do sedna, czyli do tego, co najbardziej interesuje deweloperów i firmy: ile to kosztuje. Standardowe stawki API dla Grok 4.3 to:
- 1,25 dol. za milion tokenów wejściowych,
- 2,50 dol. za milion tokenów wyjściowych.
Dla porównania: Grok 4.2 startował z poziomu 2 dol. za milion tokenów wejściowych i 6 dol. za milion wyjściowych. Mówimy więc o około 40-procentowej obniżce po stronie inputu i 60-procentowej po stronie outputu.
Na tle konkurencji Grok 4.3 ląduje w dolnej połowie stawki, bliżej chińskich modeli niż topowych, drogich modeli ze Stanów Zjednoczonych. OpenAI i Anthropic za swoje najmocniejsze modele potrafią liczyć po kilkanaście-kilkadziesiąt dolarów za milion tokenów wyjściowych. Tutaj mamy 2,50 dol.
Jest jednak haczyk - a właściwie kilka.
Po pierwsze, xAI wprowadza pojęcie „reasoning tokens”. To tokeny generowane podczas wewnętrznego „myślenia” modelu. Użytkownik ich nie widzi, ale… płaci za nie tak samo, jak za zwykłe tokeny odpowiedzi. Innymi słowy: płacisz nie tylko za to, co model ci powie, ale też za to, że w ogóle myślał zanim to powiedział. Przy prostych zadaniach różnica może być niewielka, ale przy długich, złożonych procesach agentowych - to może już być odczuwalne.
Po drugie, xAI wprowadza dodatkowe opłaty za wywołania narzędzi. Samo zużycie tokenów w narzędziach jest liczone normalnie, ale każde wywołanie ma stałą opłatę: 5 dol. za 1000 wywołań Web Search lub Code Execution oraz 10 dol. za 1000 wywołań narzędzia do obsługi plików. Dla dużych systemów agentowych, które intensywnie korzystają z narzędzi, to jest koszt, który trzeba wliczyć w budżet.
Po trzecie, xAI wprowadza coś, czego jeszcze nie widzieliśmy w takiej formie: opłatę za naruszenie zasad. Jeśli twoje zapytanie zostanie zablokowane przez filtry bezpieczeństwa zanim model cokolwiek wygeneruje to xAI naliczy 0,05 dol. opłaty za „violation”. To jest ruch, który może budzić kontrowersje - bo oznacza, że za nieudane, zablokowane zapytanie też można zapłacić. Z punktu widzenia xAI to sposób na zniechęcenie do masowego spamowania systemu treściami na granicy regulaminu. Z punktu widzenia użytkownika - kolejny element, który trzeba mieć z tyłu głowy.
Z drugiej strony są też mechanizmy obniżające koszty. xAI oferuje tzw. prompt caching - jeśli wielokrotnie używasz tego samego promptu to możesz płacić za niego tylko 0,20 dol. za milion tokenów. Dla dużych systemów, które bazują na powtarzalnych kontekstach, to może być realna oszczędność.
Benchmarki: świetny prawnik, przeciętny matematyk, śpiący agent
No dobrze, ale jak Grok 4.3 wypada w praktyce? Tu robi się ciekawie, bo obraz jest mocno niejednoznaczny. Z jednej strony niezależne firmy oceniające modele - takie jak Vals AI czy Artificial Analysis - pokazują, że Grok 4.3 potrafi błyszczeć w bardzo konkretnych dziedzinach. Na benchmarku CaseLaw v2 model osiąga około 79,3 proc. skuteczności i wskakuje na pierwsze miejsce. Podobnie na indeksie CorpFin, związanym z finansami korporacyjnymi. To sugeruje, że „always-on reasoning” faktycznie dobrze sprawdza się w gęstych, logicznych dziedzinach, takich jak prawo czy finanse.
Na benchmarku agentowym GDPval-AA Grok 4.3 osiąga Elo na poziomie 1500, wyprzedzając m.in. Gemini 3.1 Pro i GPT-5.4 mini. To z kolei wskazuje, że w zadaniach typu „agent ma coś zrobić, korzystając z narzędzi” model potrafi być bardzo skuteczny.
Z drugiej strony są obszary, w których Grok 4.3 wypada słabo albo wręcz regresuje względem poprzedników. Firma Andon Labs, która testuje modele w symulacjach retailowych (benchmark Vending-Bench 2), określiła Groka 4.3 jako „duży regres” i zarzuciła mu „narcolepsy problems” - model woli nic nie robić przez kilka dni symulacji zamiast podejmować wymagane działania.
Vals AI zwraca uwagę, że choć Grok poprawił się w niektórych zadaniach programistycznych, to wciąż jest słaby w ogólnym kodowaniu i ma duże problemy z trudną matematyką - na benchmarku ProofBench osiąga zaledwie 11 proc.
W skrócie: Grok 4.3 wygląda jak model, który został mocno podciągnięty pod konkretne zastosowania (prawo, finanse, agentowe workflowy), ale nie jest „idealnym ogólniakiem”. I xAI wcale nie udaje, że jest inaczej - w materiałach pojawia się wręcz teza, że firma stawia na „wyspecjalizowaną błyskotliwość i ekstremalną efektywność kosztową”, a nie na perfekcyjnie zbalansowanego generalistę.
Wizerunek, kontrowersje i pytanie: czy firmy zaufają Grokowi?
Jest jeszcze jeden element, którego nie da się pominąć, jeśli mówimy o Groku w kontekście zastosowań enterprise: reputacja. Poprzednie wersje Groka zdążyły już zaliczyć kilka poważnych wpadek. Chatbot na X potrafił przedstawiać się jako „MechaHitler”, generować treści antysemickie, seksualizowane deepfake’i i odwoływać się do skrajnie prawicowych narracji. W pewnym momencie okazało się, że model w wersji na X sprawdzał konto Muska, zanim odpowiedział na niektóre pytania - co tylko dolało oliwy do ognia w dyskusji o jego stronniczości.
xAI twierdzi, że pracuje nad tymi problemami. W dokumentacji Groka 4.3 pojawia się m.in. zapis w system promptcie, że model „nie przypisuje szerokich pozytywnych/negatywnych ocen całym grupom ludzi”. To brzmi jak próba załatania części wcześniejszych zachowań. Ale czy to wystarczy, żeby przekonać duże firmy, szczególnie te wrażliwe na kwestie wizerunkowe? To zupełnie osobne pytanie.
Z punktu widzenia korporacji, które rozważają wdrożenie Groka 4.3 do pracy z danymi prawnymi czy finansowymi, liczą się trzy rzeczy: bezpieczeństwo danych, stabilność zachowania i reputacja dostawcy. xAI chwali się certyfikacją SOC 2 Type II, zgodnością z HIPAA (dla zastosowań medycznych) i zgodnością z RODO. Technicznie więc jest enterprise-ready. Ale cień wcześniejszych skandali wisi nad marką Grok i trudno udawać, że go nie ma.
Grok 4.3 to nie jest zabójca GPT, ale może być zabójczo opłacalny
xAI nie udaje, że Grok 4.3 jest najinteligentniejszym modelem na rynku. Benchmarki pokazują jasno: OpenAI i Anthropic wciąż prowadzą w wielu kategoriach. Ale Grok 4.3 gra w innej lidze - w lidze „value for money”.
Czy to jest model, który „zabije” GPT-5 czy Claude’a? Nie. Ale może być modelem, który zabije kilka biznesplanów - tych, które zakładały, że „poważne AI musi być drogie”. Jeśli xAI utrzyma tę politykę cenową i jednocześnie będzie dalej poprawiać jakość to Grok 4.3 i jego następcy mogą stać się tym, czym dla rynku telefonów były kiedyś agresywnie wycenione chińskie sztandarowce: może nie najładniejsze, może nie najbardziej dopieszczone, ale za to bardzo trudne do zignorowania.