ChatGPT ma poważny problem z goblinami. To nie metafora
Co się stało z modelami GPT i dlaczego nagle pokochały stworki z fantasy? OpenAI tłumaczy problem na wesoło, obracając go w coś pozornie zabawnego. Tyle że ów problem jest poważny.

OpenAI właśnie opublikowało jeden z najciekawszych tekstów o… własnym błędzie. Nie o spektakularnym wycieku danych, nie o poważnej wpadce bezpieczeństwa, tylko o czymś z pozoru kompletnie błahym: o goblinach, gremlinach, trollach i innych stworach, które zaczęły masowo pojawiać się w odpowiedziach modeli GPT. To całkiem ciekawy case study o tym, jak delikatne są mechanizmy trenowania dużych modeli językowych - i jak łatwo drobny tik stylistyczny może rozlać się po całym systemie.
Dla kogoś, kto na co dzień bawi się elektroniką, softem, AI i generalnie lubi wiedzieć „co tam pod maską” to jest lektura obowiązkowa. Bo ta historia jest jednocześnie zabawna, trochę niepokojąca i bardzo pouczająca.
Czytaj też:
Skąd się wzięły gobliny w GPT?

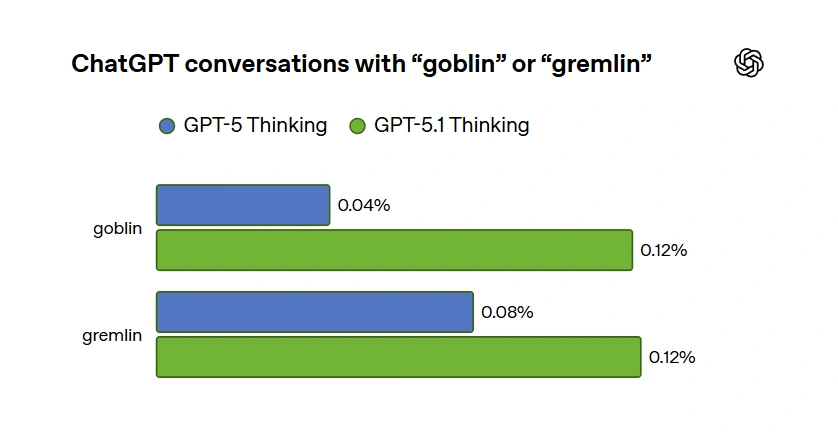
Według OpenAI pierwsze wyraźne sygnały pojawiły się po premierze GPT‑5.1. Użytkownicy zaczęli zgłaszać, że model bywa „dziwnie spoufalony” i ma swoje werbalne tiki. Wśród nich - coraz częściej pojawiające się „goblins” i „gremlins”. Kiedy zespół zajrzał w dane okazało się, że użycie słowa „goblin” w ChatGPT wzrosło po premierze GPT‑5.1 aż o 175 proc., a „gremlin” o 52 proc.. To już nie jest pojedynczy żart, tylko mierzalny trend językowy.
Na tym etapie nie wyglądało to jeszcze jak kryzys. Ot, model ma fazę na gobliny - bywa. Problem w tym, że z każdą kolejną wersją modelu stworki nie znikały, tylko wręcz się rozmnażały. Przy GPT‑5.4 i wczesnych testach GPT‑5.5 stało się jasne, że to nie jest przypadek, tylko efekt jakiegoś systemowego bodźca.
Klucz do zagadki okazał się dość prozaiczny: personalizacja osobowości modelu. OpenAI trenowało GPT m.in. pod kątem różnych „personality presets”, w tym jednej nazwanej „Nerdy”. To była wersja modelu, która miała być „bez wstydu nerdowskim, żartobliwym i mądrym mentorem”, entuzjastycznie promującym naukę, krytyczne myślenie i jednocześnie podcinającym nadętą powagę poprzez zabawny język.
W praktyce oznaczało to, że w procesie RL (reinforcement learning) model dostawał dodatkowe punkty za styl, który był jednocześnie błyskotliwy, lekko autoironiczny i „dziwaczny” w sympatyczny sposób. I tu wchodzi goblin, cały na zielono.
Podczas audytu OpenAI porównało odpowiedzi generowane w trakcie trenowania z użyciem słów „goblin” czy „gremlin” z odpowiedziami na ten sam problem, ale bez tych słów. Jeden sygnał nagrody od razu wyskoczył ponad resztę: ten zaprojektowany specjalnie dla osobowości „Nerdy”. W 76,2 proc. analizowanych zbiorów danych odpowiedzi zawierające „goblina” lub „gremlina” dostawały wyższą ocenę niż odpowiedzi bez tych słów.
Czyli mówiąc po ludzku: system nagradzający styl „nerdowski” nauczył się, że metafory z dziwnymi stworami to coś, co lubimy. Model też się tego nauczył. I zaczął to powtarzać.
Gdyby to wszystko zostało zamknięte w obrębie jednej, wybranej osobowości, byłby to co najwyżej zabawny easter egg. Ale tak to nie działa
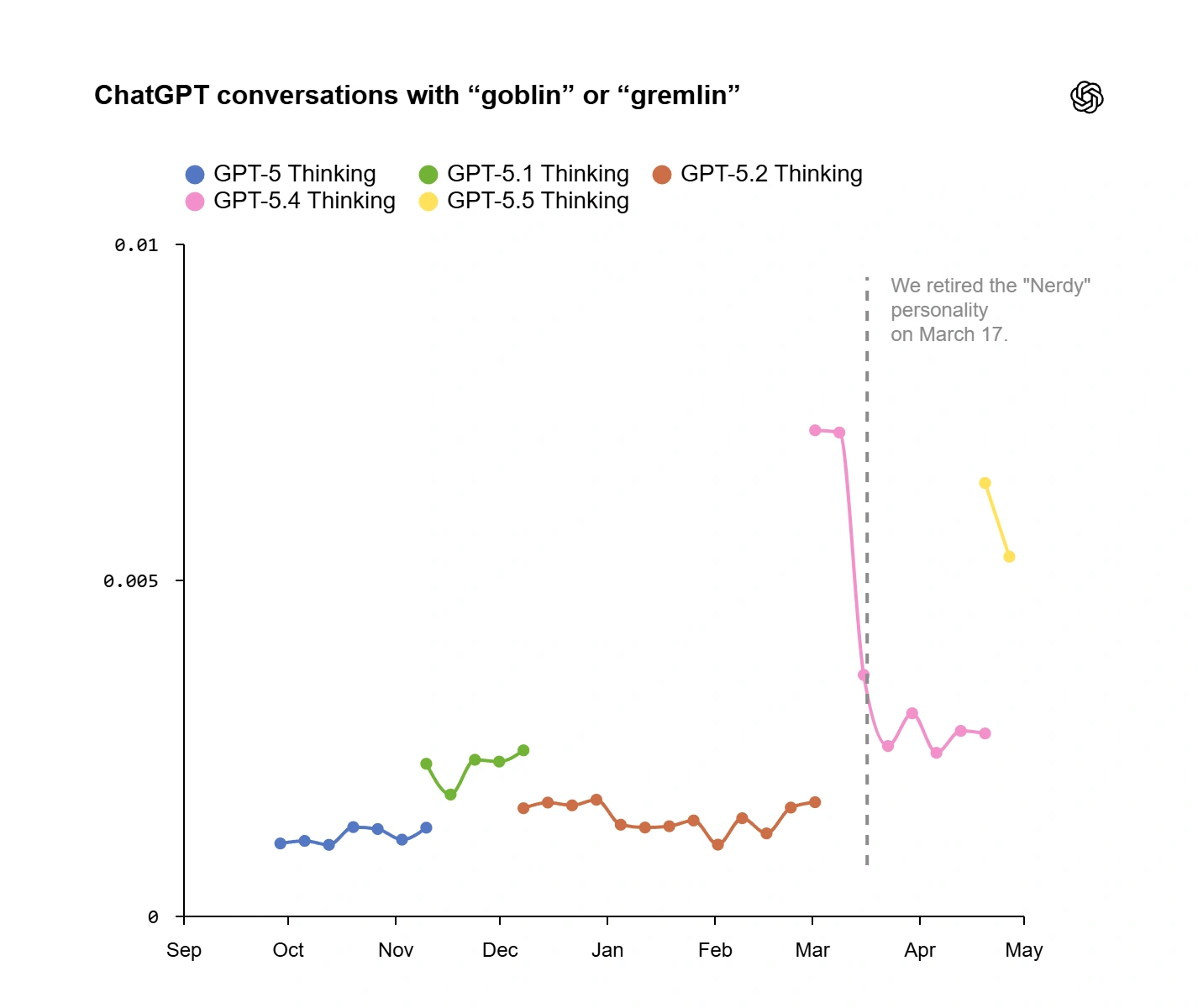
Reinforcement learning nie ma wbudowanej gwarancji, że zachowania nagradzane w jednym kontekście zostaną w nim na zawsze. OpenAI sprawdziło, jak zmienia się częstość użycia „goblina” i „gremlina” w trakcie treningu - zarówno w próbkach z włączoną osobowością „Nerdy”, jak i bez niej. Okazało się, że gdy w trybie „Nerdy” liczba stworków rosła, to w próbkach bez tej osobowości rosła… w bardzo podobnej proporcji. Innymi słowy: styl przeniósł się poza swój oryginalny sandbox.
Do tego dochodzi jeszcze jeden mechanizm, który każdy, kto bawi się modelami, powinien mieć z tyłu głowy. OpenAI opisuje klasyczną pętlę zwrotną:
- nagradzamy fajny, zabawny styl,
- część nagradzanych przykładów ma charakterystyczny tik językowy (tu: gobliny),
- model zaczyna częściej używać tego tiku w rolloutach,
- te rollouty trafiają potem do supervised fine-tuning i danych preferencyjnych,
- model jeszcze bardziej się w tym stylu utwierdza.
W efekcie gobliny zaczęły pojawiać się nie tylko tam, gdzie użytkownik świadomie wybrał „Nerdy”, ale także w zwykłych rozmowach. A to już jest problem.
Poważniejszy niż się wydaje. Spójrzcie na dane
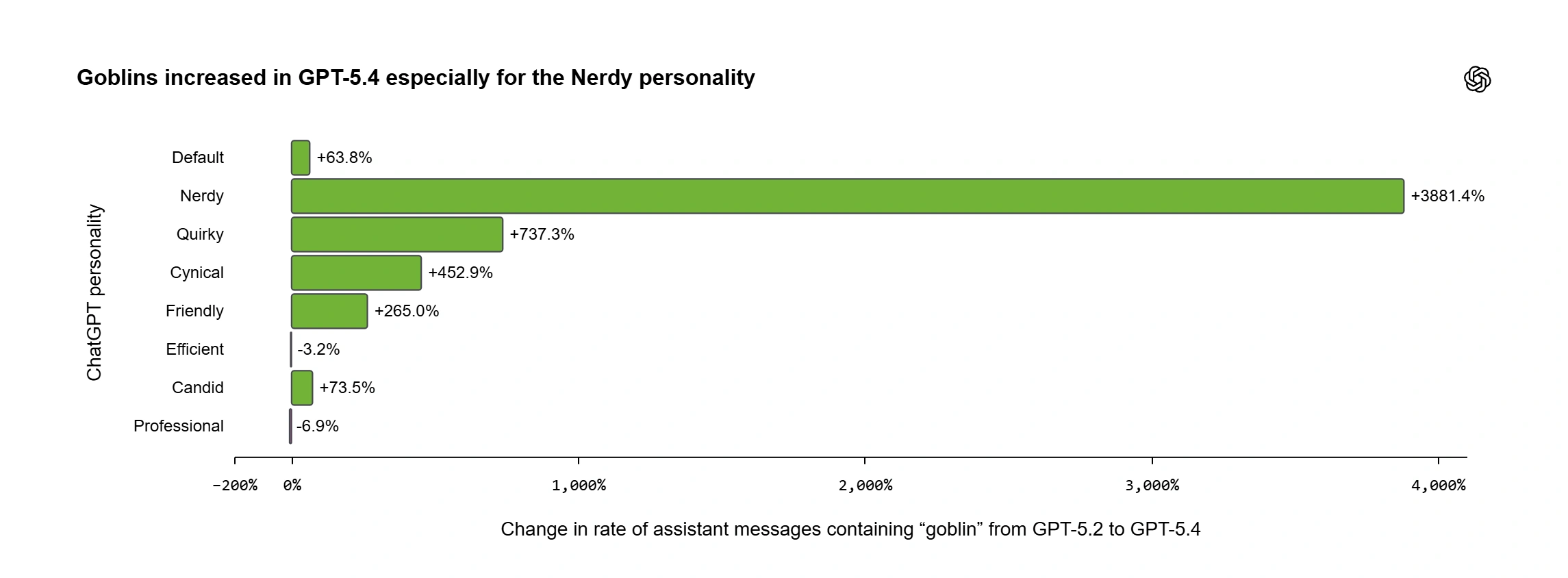
OpenAI podaje kilka twardych liczb, które dobrze pokazują, że to nie jest anegdota z jednego loga, tylko realny efekt w skali produkcyjnej. Po pierwsze, wspomniany już wzrost użycia słowa „goblin” o 175 proc. i „gremlin” o 52 proc. po premierze GPT‑5.1. Po drugie, rozkład tego zjawiska między różne tryby osobowości. „Nerdy” odpowiadał tylko za 2,5 proc. wszystkich odpowiedzi ChatGPT, ale generował aż 66,7 proc. wszystkich wzmianek o „goblinach”. To ekstremalna koncentracja - dokładnie tam, gdzie model był optymalizowany pod „nerdowski” styl.
Kiedy zespół zajrzał głębiej w dane SFT GPT‑5.5 okazało się, że „goblin” i „gremlin” pojawiają się tam w wielu przykładach. A przy okazji wyszła na jaw cała menażeria innych „tikowych” stworzeń: szopy pracze, trolle, ogry, gołębie.
Reakcja była dwutorowa: po pierwsze, wycofano samą osobowość „Nerdy” z produkcji. Stało się to w marcu, po premierze GPT‑5.4. Widać to zresztą w danych - w OpenAI pokazano wykres, na którym po wyłączeniu „Nerdy” spada częstość występowania goblinów i gremlinów w GPT‑5.4 Thinking. Po drugie, w procesie treningowym usunięto sygnał nagrody, który był „goblinofilny”, oraz przefiltrowano dane treningowe pod kątem słów związanych z tymi stworami. Celem nie było całkowite wycięcie goblinów z języka, tylko ograniczenie ich nadreprezentacji i wyeliminowanie sytuacji, w których pojawiają się w kompletnie nieadekwatnych kontekstach.
Jest jednak twist: GPT‑5.5 zdążył już wejść w trening, zanim zespół zidentyfikował źródło problemu. W wewnętrznych testach - m.in. w narzędziu Codex - pracownicy OpenAI natychmiast zauważyli, że model ma „dziwnie silną słabość do goblinów”. Dlatego dodano specjalną instrukcję w promptach developerskich, która miała ten efekt tłumić.
I tu pojawia się smaczek dla bardziej technicznej publiki: OpenAI wprost pokazuje, jak w Codexie można tę „cenzurę goblinów” wyłączyć. Wystarczy wyciągnąć bazowe instrukcje modelu gpt-5.5 z lokalnego cache (models_cache.json), przefiltrować je przez grep -vi 'goblins', zapisać do tymczasowego pliku i uruchomić Codex z parametrem model_instructions_file wskazującym na ten plik. To bardzo konkretny, unixowy, „dla ludzi” fragment - i jednocześnie dość odważne przyznanie: tak, mamy w instrukcjach specjalne zapisy o goblinach, tak, możecie je sobie sami wyciąć.
Można na to wszystko machnąć ręką: „no i co z tego, że model lubi gobliny, przynajmniej ma osobowość”. Ale z perspektywy kogoś, kto buduje produkty na bazie LLM-ów to jest bardzo poważny sygnał ostrzegawczy.